How to build Data Warehouse on Hadoop cluster (Part 1)
- 15 minsIn their business activities, business owners always need to make decisions, the right decisions will help the business stabilize and develop, on the contrary, wrong decisions will lead to losses or even bankruptcy. Business Intelligence (BI) is a system that synthesizes information, provides smart analytical reports, builds predictive models from data, allowing business owners to have a comprehensive view of their business, thereby making decisions that are beneficial to business operations. In this article, I will introduce to you about Data warehouse (DWH) which is likened to “stomach”, is the warehouse that stores all the data of the BI system, due to the capacity of the article, I will split it into 2 parts: Part 1 is the installation instructions, part 2 is the DWH application for a specific problem.
Contents
- Overview
- Design architecture
- Install Spark
- Install Postgresql
- Configuring Spark Thrift Server (Hive)
- Install DBT
- Install Superset
- Install Airflow
- Conclusion
I am currently consulting, designing and implementing data analysis infrastructure, Data Warehouse, Lakehouse for individuals and organizations in need. You can see and try a system I have built here. Please contact me via email: lakechain.nguyen@gmail.com. Thank you!
Overview
According to the definition from Oracle, Data Warehouse is a type of data management system designed to support analytical activities and business intelligence (BI). Data in a data warehouse is structured like a database, but there are some differences between the two systems as follows:
- Database is used for data collection purposes, used for daily activities, while DWH is used for data analysis.
- Data in the Database is added, edited, and deleted directly by applications, while data in DWH is imported from many different sources.
- Tables in the Database are designed in a standard form to avoid redundancy and ensure accuracy when adding, editing, and deleting, while in DWH data can be repeated for faster querying but limited when editing data.
- Database is optimized for queries that add, edit, delete, and comply with ACID to ensure data integrity, while DWH is optimized for complex, in-depth analytical and synthetic queries that do not always comply with ACID.
Design Architecture
There are many ways to design a Data Warehouse, it will depend on each person’s usage needs, here I rely on the technical descriptions of Dune Analyst a startup that provides Blockchain data analysis infrastructure, valued at up to 1 billion dollars in February 2022.
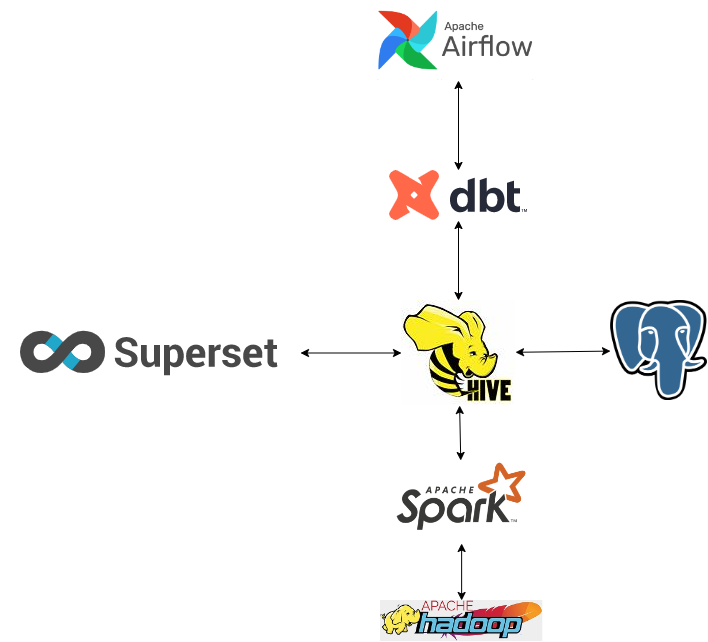
- DBT is a framework that allows developers to quickly build data models and data transformations using the familiar SQL language.
- HDFS acts as the data storage infrastructure for the entire system, providing high scalability, availability and fault tolerance.
- Spark is a computing framework that allows applications to run in parallel and distributed across multiple computers to increase efficiency in processing big data. Spark is hundreds of times faster than Mapreduce thanks to its ability to use RAM to store intermediate data instead of reading and writing them on hard drives.
- Hive in this system acts as an interface layer that allows other applications to use Spark and HDFS using SQL language.
- Postgresql is the database that stores Metadata for Hive.
- Superset is a tool to present data in the form of tables and charts in analytical dashboards.
- Airflow provides the ability to manage, schedule workflow execution, automate processes, support developers to monitor and detect errors, especially in complex, interdependent processing flows.
Install Spark
Go to Spark’s homepage here to get the download link. At the time of writing this article, the latest version of spark is 3.3.4, but when testing, I found that this version is not compatible with DBT and Hive, so I used a lower version of spark, 3.3.2.
Note: Since we already have a Hadoop cluster (you can review the instructions here), we only need to install Spark on 1 node (mine is on
node01), when running a Spark job, we configure--master yarnso that the job can run on all nodes.
$ wget https://archive.apache.org/dist/spark/spark-3.3.2/spark-3.3.2-bin-hadoop3.tgz
$ tar -xzvf spark-3.3.2-bin-hadoop3.tgz
$ mv spark-3.3.2-bin-hadoop3 /lib/spark
$ mkdir /lib/spark/logs
$ chgrp hadoop -R /lib/spark
$ chmod g+w -R /lib/spark
Configure environment variables in file /etc/bash.bashrc:
export SPARK_HOME=/lib/spark
export PATH=$PATH:$SPARK_HOME/bin
Update environment variables
$ source /etc/bash.bashrc
Create the $SPARK_HOME/conf/spark-env.sh file:
cp $SPARK_HOME/conf/spark-env.sh.template $SPARK_HOME/conf/spark-env.sh
Add the classpath configuration to the newly created $SPARK_HOME/conf/spark-env.sh file:
export SPARK_DIST_CLASSPATH=$(hadoop classpath)
Check if Spark is running in yarn mode:
spark-shell --master yarn --deploy-mode client
Result:
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.3.2
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 11.0.17)
scala>
Install Postgresql
You can install Posgresql directly or use Docker, here I will install directly on node01 according to the instructions on the homepage here.
Enable postgresql service
$ service postgresql start
By default, we can only connect to Postgresql on the localhost machine through the user postgres:
Switch to the postgres user
$ su postgres
Enter the Sql command interface:
[postgres]$ psql
Reset the password for the postgres account:
postgres=# ALTER USER postgres WITH PASSWORD 'password';
To be able to connect from other machines (remote), we need to edit the configuration as follows:
- Edit the configuration in:
postgresql.conf
listen_addresses = '*'
- Add the following configuration to the end of the file:
pg_hba.conf
host all all 0.0.0.0/0 md5
Note: to know the location of the 2 configuration files, we need to use the commands
show config_file;andshow hba_file;on the Sql command.
Restart posgresql
$ service postgresql restart
Check if you can connect to postgresql via ip:
$ psql -h node01 -p 5432 -U postgres -W
Configure Spark Thrift Server (Hive)
The Spark installation has built-in Thrift Server (Hive), allowing other applications to work with Spark through Hive’s SQL language. We need to configure the data to be stored on HDFS and the metadata to be stored on postgresql as follows:
$SPARK_HOME/conf/hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.db.type</name>
<value>postgres</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>hdfs://node01:9000/user/hive/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:postgresql://node01:5432/metastore</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.postgresql.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>password</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>fs.hdfs.impl.disable.cache</name>
<value>true</value>
</property>
</configuration>
$SPARK_HOME/sbin/start-hive.sh
./start-thriftserver.sh --master yarn --deploy-mode client \
--driver-memory 4g \
--executor-memory 6g \
--executor-cores 4 \
--num-executors 2 \
--conf "spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension" \
--conf "spark.sql.catalog.spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog"
Thrift server will run as a Spark Job on Yarn so you can customize the appropriate resources (RAM capacity, number of cores, number of excurtors…) when running.
Download postgresql driver to the folder $SPARK_HOME/jars/:
$ cd $SPARK_HOME/jars/
$ wget https://jdbc.postgresql.org/download/postgresql-42.5.1.jar
Download Delta library to folder $SPARK_HOME/jars/:
$ cd $SPARK_HOME/jars/
$ wget https://repo1.maven.org/maven2/io/delta/delta-core_2.12/2.3.0/delta-core_2.12-2.3.0.jar
$ wget https://repo1.maven.org/maven2/io/delta/delta-storage/2.3.0/delta-storage-2.3.0.jar
Create user hive and directory warehouse on HDFS:
$ useradd -g hadoop -m -s /bin/bash hive
[hive]$ hdfs dfs -mkdir -p /user/hive/warehouse
Create user hive and database metastore on Postgresql:
postgres=# CREATE DATABASE metastore;
postgres=# CREATE USER hive with password 'password';
postgres=# GRANT ALL PRIVILEGES ON DATABASE metastore to hive;
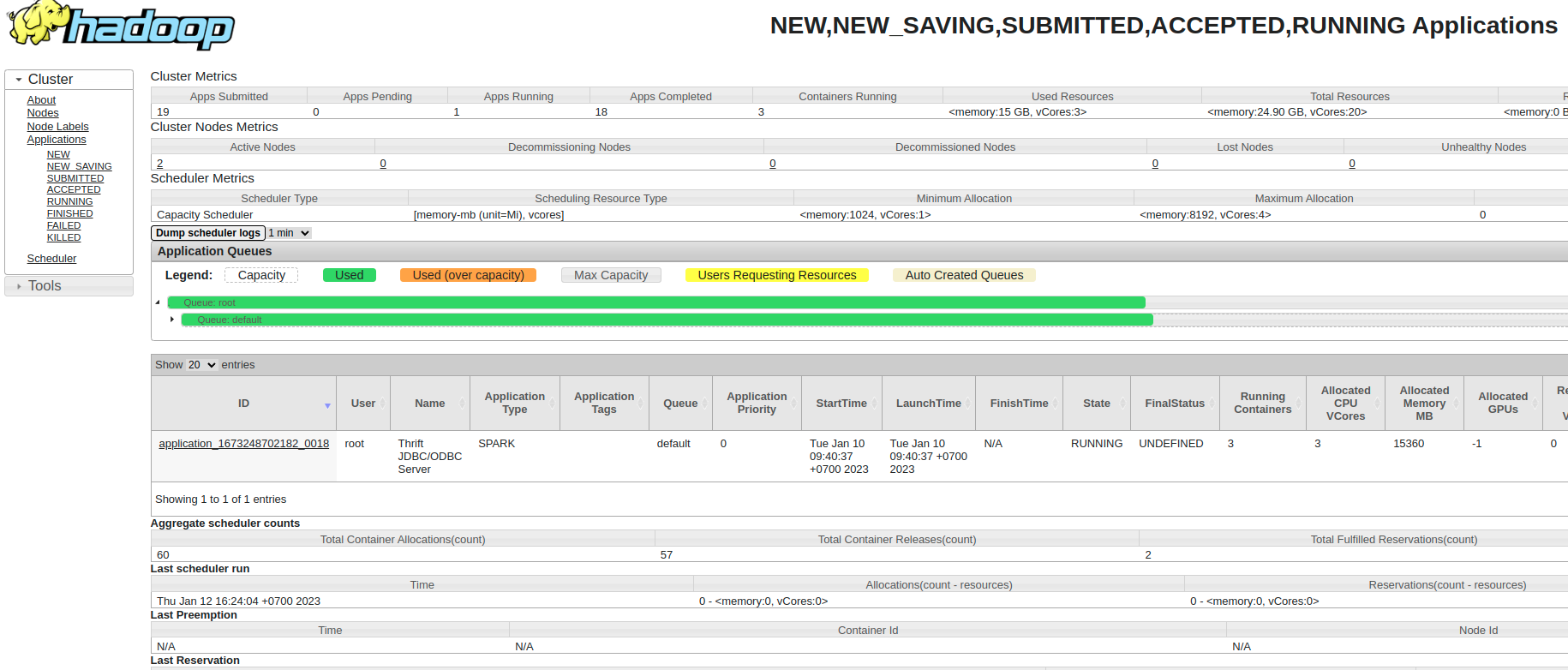
Run Thrift Server
$ chmod +x $SPARK_HOME/sbin/start-hive.sh
$ $SPARK_HOME/sbin/start-hive.sh
Job was run on Yarn at http://172.24.0.2:8088/cluster/scheduler
Turn off Thift Server:
$ $SPARK_HOME/sbin/stop-thriftserver.sh
Install DBT
For speed, I will use the DBT example project available on Github here. I will explain more about this project in the next post.
Use git to clone the project to your computer:
$ git clone https://github.com/dbt-labs/jaffle_shop.git
Install development environment and libraries via Anaconda (you can refer to Anaconda tại đây)
$ conda create -n dbt_example python=3.9
$ conda activate dbt_example
(dbt_example) $ pip install dbt-spark[PyHive]
Configure connection to Hive server in file ~/.dbt/profiles.yml:
jaffle_shop:
outputs:
dev:
type: spark
method: thrift
host: node01
port: 10000
user: hive
dbname: jaffle_shop
schema: dbt_alice
threads: 4
prod:
type: spark
method: thrift
host: node01
port: 10000
user: hive
dbname: jaffle_shop
schema: dbt_alice
threads: 4
target: dev
Run the following commands in turn to migrate the models into tables on the DWH.
$ dbt debug
$ dbt seed
$ dbt run
$ dbt test
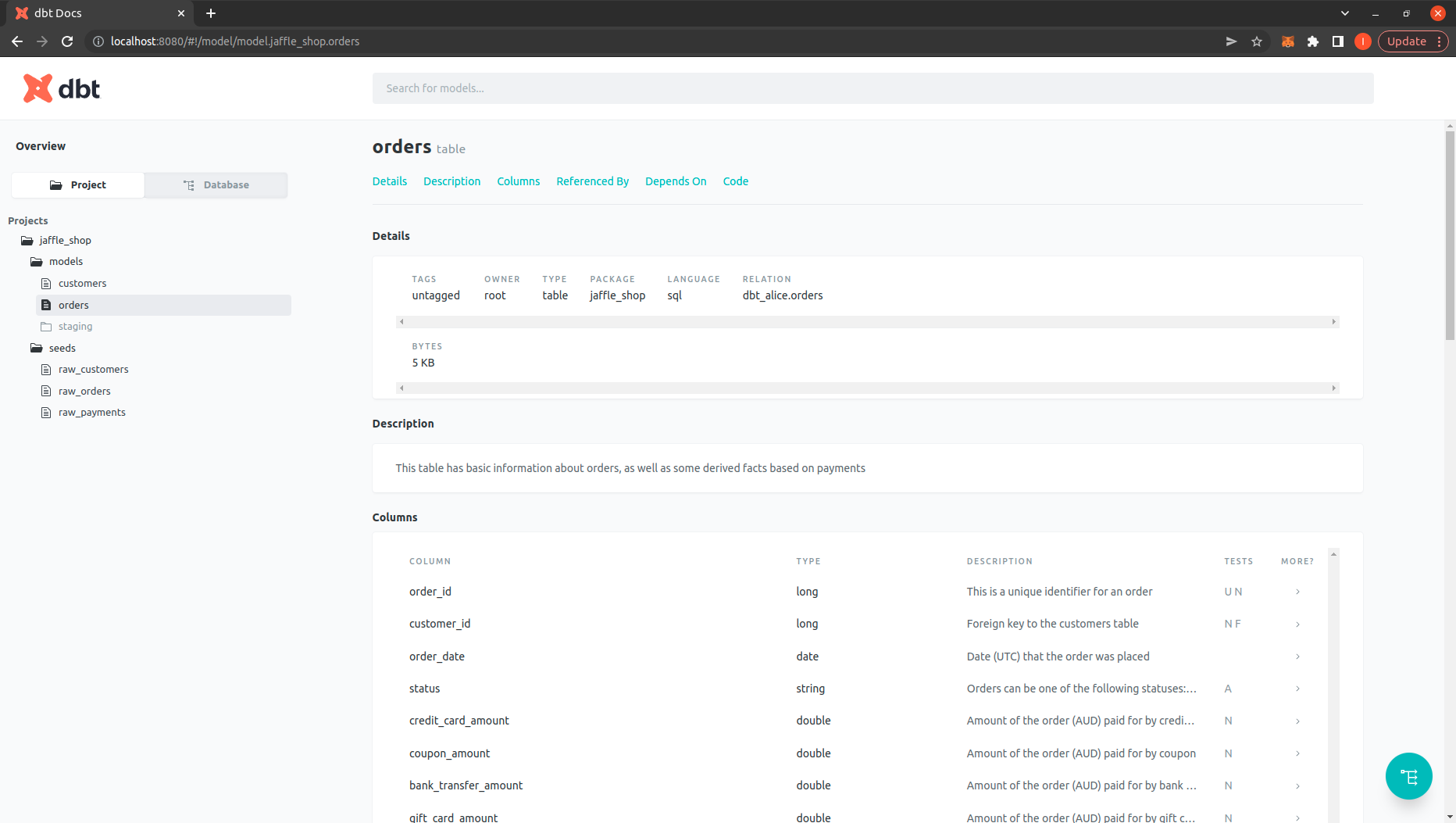
$ dbt docs generate
$ dbt docs serve
Check the DBT project is running on http://localhost:8080/
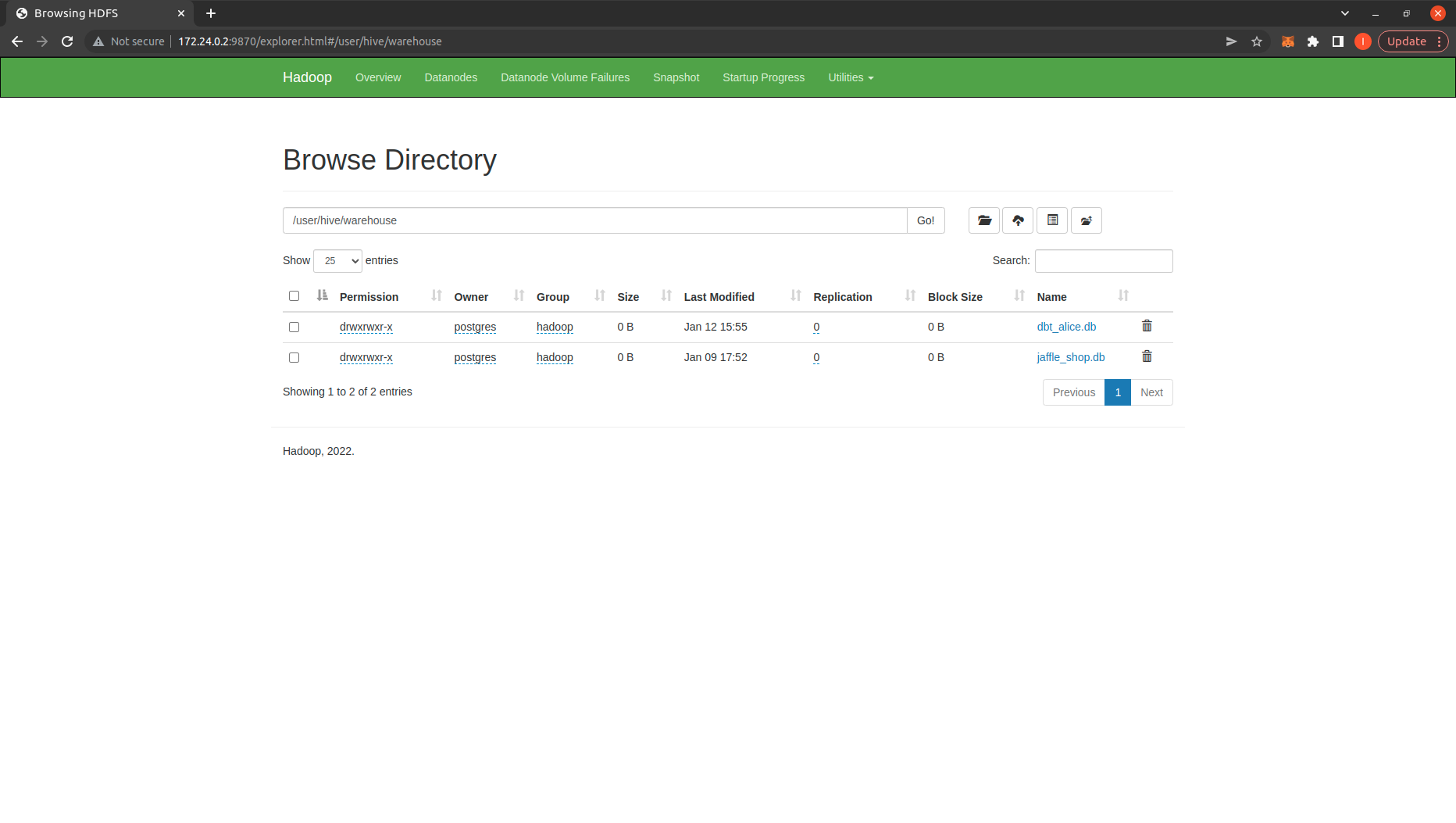
Check the warehouse directory on HDFS: http://172.24.0.2:9870/explorer.html#/user/hive/warehouse we can see that there are data databases created:
Install Superset
We will use Superset to view the migrated data on DWH. I will install Superset via docker
docker run -d --name superset --hostname superset --network hadoop apache/superset
docker exec -it superset superset fab create-admin \
--username admin \
--firstname Superset \
--lastname Admin \
--email admin@superset.com \
--password admin
Check on Superset’s web interface: http://172.24.0.4:8088/
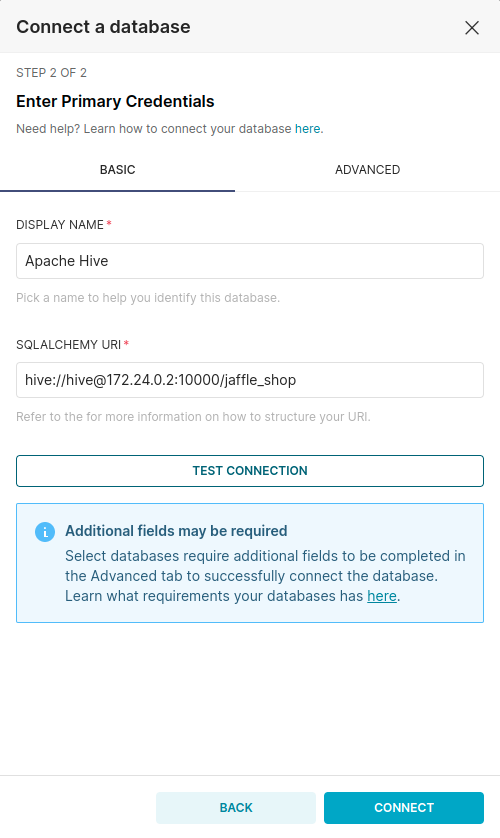
Log in with account admin/admin, then go to Settting \ Databases Connections to create a new Connection Database. In step 1, you choose Supported Database as Apache Hive, in the SQLALCHEMY URI section, you enter the url of Hive: hive://hive@172.24.0.2:10000/jaffle_shop then select Connect.
To use queries into the DWH, you use the SQL Lab interface on Superset: 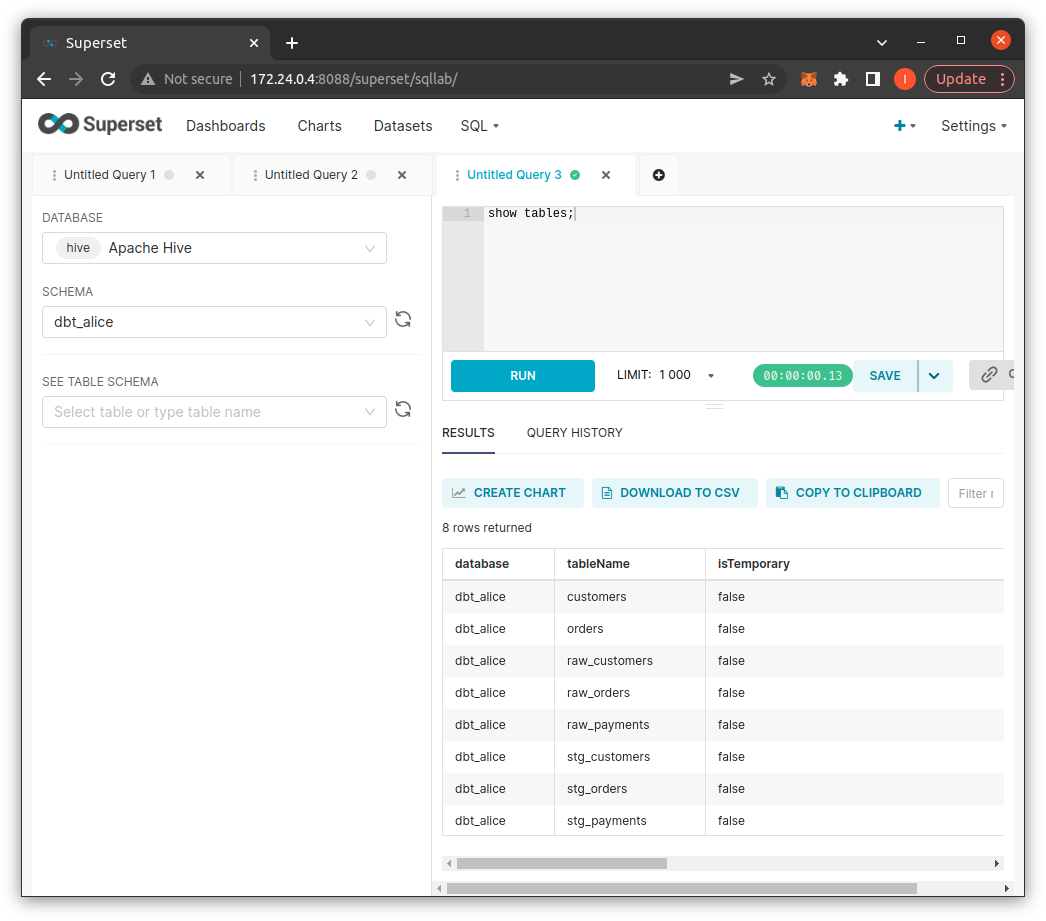
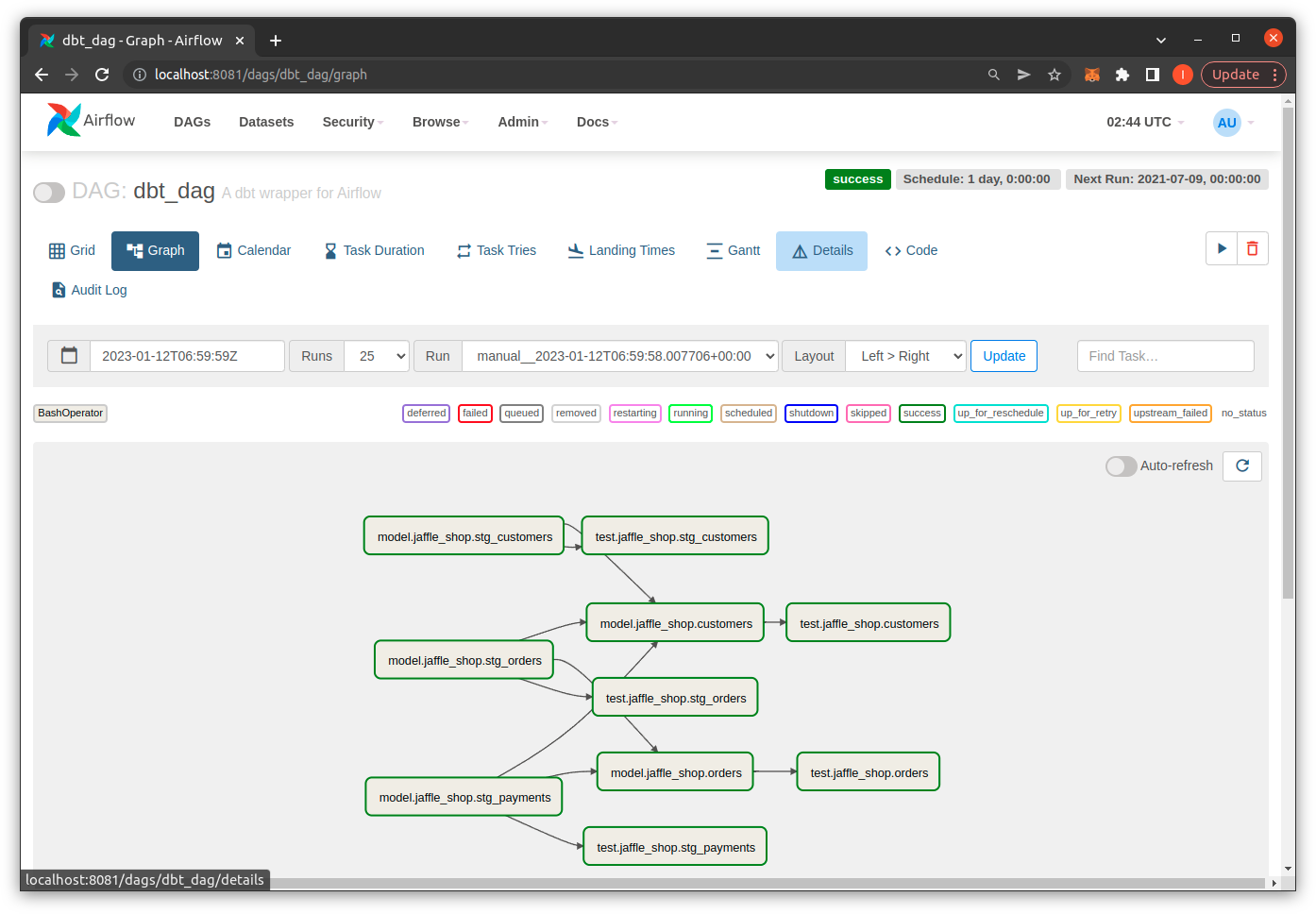
Install Airflow
For simplicity, you can install Airflow directly in the dbt jaffle_shop project, you can see the installation instructions here
$ export AIRFLOW_HOME=~/airflow
$ export AIRFLOW_VERSION=2.5.0
$ export PYTHON_VERSION="$(python --version | cut -d " " -f 2 | cut -d "." -f 1-2)"
$ export CONSTRAINT_URL="https://raw.githubusercontent.com/apache/airflow/constraints-${AIRFLOW_VERSION}/constraints-${PYTHON_VERSION}.txt"
$ pip install "apache-airflow==${AIRFLOW_VERSION}" --constraint "${CONSTRAINT_URL}"
Create DAG file for jaffle_shop project in directory ~/airflow/dags/jaffle_shop/pipeline.py
from datetime import datetime, timedelta
import json
from airflow import DAG
from airflow.operators.bash import BashOperator
dag = DAG(
dag_id='dbt_dag',
start_date=datetime(2020, 12, 23),
description='A dbt wrapper for Airflow',
schedule_interval=timedelta(days=1),
)
def load_manifest():
local_filepath = "jaffle_shop/target/manifest.json"
with open(local_filepath) as f:
data = json.load(f)
return data
def make_dbt_task(node, dbt_verb):
"""Returns an Airflow operator either run and test an individual model"""
DBT_DIR = "jaffle_shop"
GLOBAL_CLI_FLAGS = "--no-write-json"
model = node.split(".")[-1]
if dbt_verb == "run":
dbt_task = BashOperator(
task_id=node,
bash_command=f"""
cd {DBT_DIR} &&
dbt {GLOBAL_CLI_FLAGS} {dbt_verb} --target prod --models {model}
""",
dag=dag,
)
elif dbt_verb == "test":
node_test = node.replace("model", "test")
dbt_task = BashOperator(
task_id=node_test,
bash_command=f"""
cd {DBT_DIR} &&
dbt {GLOBAL_CLI_FLAGS} {dbt_verb} --target prod --models {model}
""",
dag=dag,
)
return dbt_task
data = load_manifest()
dbt_tasks = {}
for node in data["nodes"].keys():
if node.split(".")[0] == "model":
node_test = node.replace("model", "test")
dbt_tasks[node] = make_dbt_task(node, "run")
dbt_tasks[node_test] = make_dbt_task(node, "test")
for node in data["nodes"].keys():
if node.split(".")[0] == "model":
# Set dependency to run tests on a model after model runs finishes
node_test = node.replace("model", "test")
dbt_tasks[node] >> dbt_tasks[node_test]
# Set all model -> model dependencies
for upstream_node in data["nodes"][node]["depends_on"]["nodes"]:
upstream_node_type = upstream_node.split(".")[0]
if upstream_node_type == "model":
dbt_tasks[upstream_node] >> dbt_tasks[node]
Note: update the jaffle_shop project directory path in
local_filepathandDBT_DIR
Run Airflow
$ airflow standalone
You go to airflow interface at http://localhost:8080/ and login with account admin and password provided on command line.
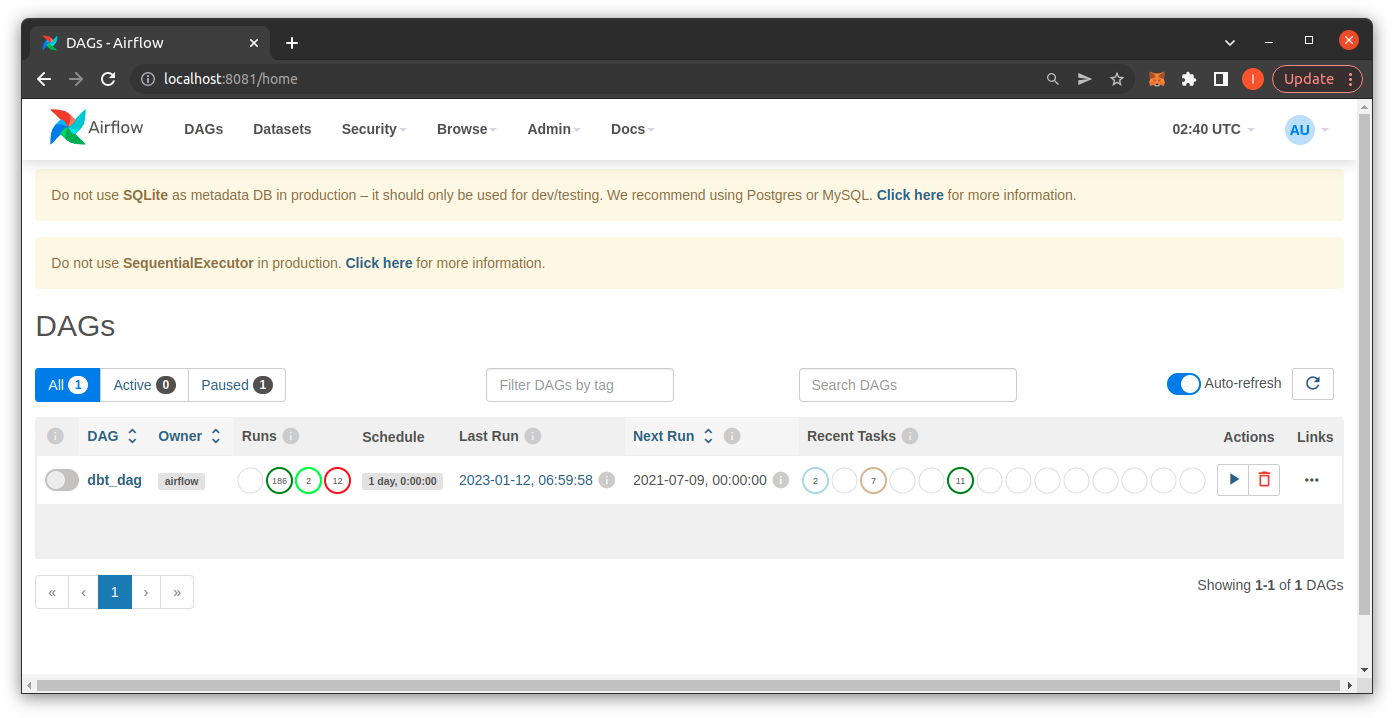
Conclusion
In this article, I have introduced to everyone the architecture and how to install a Data Warehouse on Hadoop. It’s been quite long so I will present the application of DWH in the next article. See you again.

Lake Nguyen
Founder of Chainslake