HDFS - Distributed File System
- 9 minsHDFS (Hadoop Distributed File System) is considered the foundation of the entire Hadoop ecosystem. Not only is it a data storage place, HDFS also has many important technologies used in developing distributed applications. In this article, I will explain HDFS through direct experiments with it, hoping to help you visualize it more easily.
Contents
I am currently consulting, designing and implementing data analysis infrastructure, Data Warehouse, Lakehouse for individuals and organizations in need. You can see and try a system I have built here. Please contact me via email: lakechain.nguyen@gmail.com. Thank you!
Overview
HDFS is based on the idea from the paper Google File System published in October 2003, which presented a brief description of Distributed File System with the following characteristics:
- Distributed: Data is divided into blocks and stored on many computers, but still provides an interface that allows users and applications to work as with a normal file system.
- Scalability: Storage capacity can be increased by adding new nodes (computers) to the cluster.
- Fault tolerance: Data is always guaranteed to be intact even if some nodes fail.
- High availability: Allows adding new nodes or replacing failed nodes without affecting users and applications in use.
- High performance: Can read and write simultaneously on many nodes.
Design Architecture
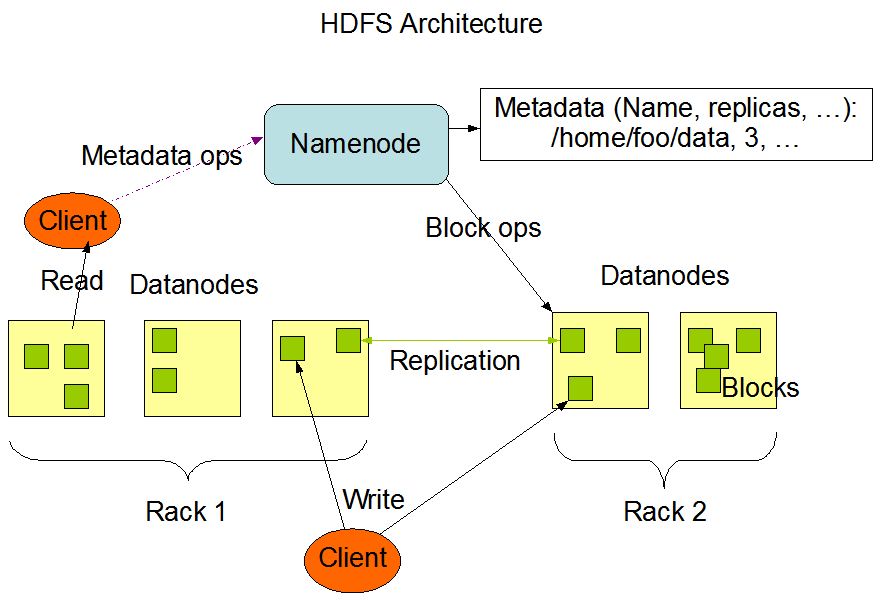
- HDFS uses Master/Slaves architecture. In the cluster, there is a Master node called Namenode that plays the role of managing the entire system, on Namenode storing the system’s Metadata such as file name, path, access rights, number of replicas. Slaves nodes are called Datanode where the actual data is stored.
- Blocks: Each data file on HDFS will be divided into blocks and stored on Datanode according to the coordination of Namenode. The default size of each block is 128MB, users can change it in the HDFS configuration file.
- Replication: To ensure safety and increase speed when reading data, each data file on HDFS is stored in multiple copies on different nodes. The default number of copies is 3, users can change the number of copies in the HDFS configuration file on each Datanode.
Experiment with HDFS
Installation
That’s the theory, now let’s practice with HDFS. I will use the Docker Containers built in the previous article for testing, you can review the build method here.
First, you start node01 and enable bash in the container
$ docker start node01
$ docker exec -it node01 bash
On node01 I will delete the old data on hdfs and reformat it.
$ su hdfs
[hdfs]$ rm -rf ~/hadoop
[hdfs]$ $HADOOP_HOME/bin/hdfs namenode -format
After formatting, you will see a folder
~/hadoop/dfs/namecreated, this is where the system metadata will be stored.
Start Namenode and check on the web interface http://localhost:9870/
[hdfs]$ $HADOOP_HOME/bin/hdfs --daemon start namenode
Now node01 has become Namenode, when checking in the Datanodes tab on the web interface you will not see any Datanode because Datanode has not been run. Start Datanode
[hdfs]$ $HADOOP_HOME/bin/hdfs --daemon start datanode
Check again on the web interface, we will see node01 appear in the Datanodes tab. Datanode data will be stored in the directory
~/hadoop/dfs/data. Node01 is now both a Namenode and a Datanode.
Similarly, you run Datanode on node02 and node03 to get a cluster of 3 nodes.
node02
$ docker start node02
$ docker exec -it node02 bash
$ echo "127.20.0.2 node01" >> /etc/hosts # replace ip node01
$ su hdfs
[hdfs]$ rm -rf ~/hadoop
[hdfs]$ $HADOOP_HOME/bin/hdfs --daemon start datanode
Check on the web interface
http://localhost:9870/dfshealth.html#tab-datanodeto see that the system has received all 3 nodes.
By default, Namenode and Datanode will communicate with each other every 300s. I will change this configuration to 3s for the convenience of the next tests.
$HADOOP_HOME/etc/hadoop/hdfs-site.xml
<configuration>
...
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>3000</value>
</property>
</configuration>Test
- Read and write data on HDFS
Copy data to HDFS from node03
hdfs@node03:~$ echo "hello world" > test1.txt
hdfs@node03:~$ hdfs dfs -copyFromLocal test1.txt /
Note: when installing, I configured
dfs.permissions.superusergroup=hadoopanddfs.datanode.data.dir.perm=774, which means that only users of the hadoop group have read and write permissions on hdfs. If you want to use another user, you must add that user to the hadoop group on the Namenode using the commandadduser [username] hadoop
Copy data from HDFS to node02
hdfs@node02:~$ hdfs dfs -copyToLocal /test1.txt ./
hdfs@node02:~$ cat test1.txt
hello world
Checking the information of File
test1.txton HDFS, we will see that the file has 1 block and is actually stored on node03.
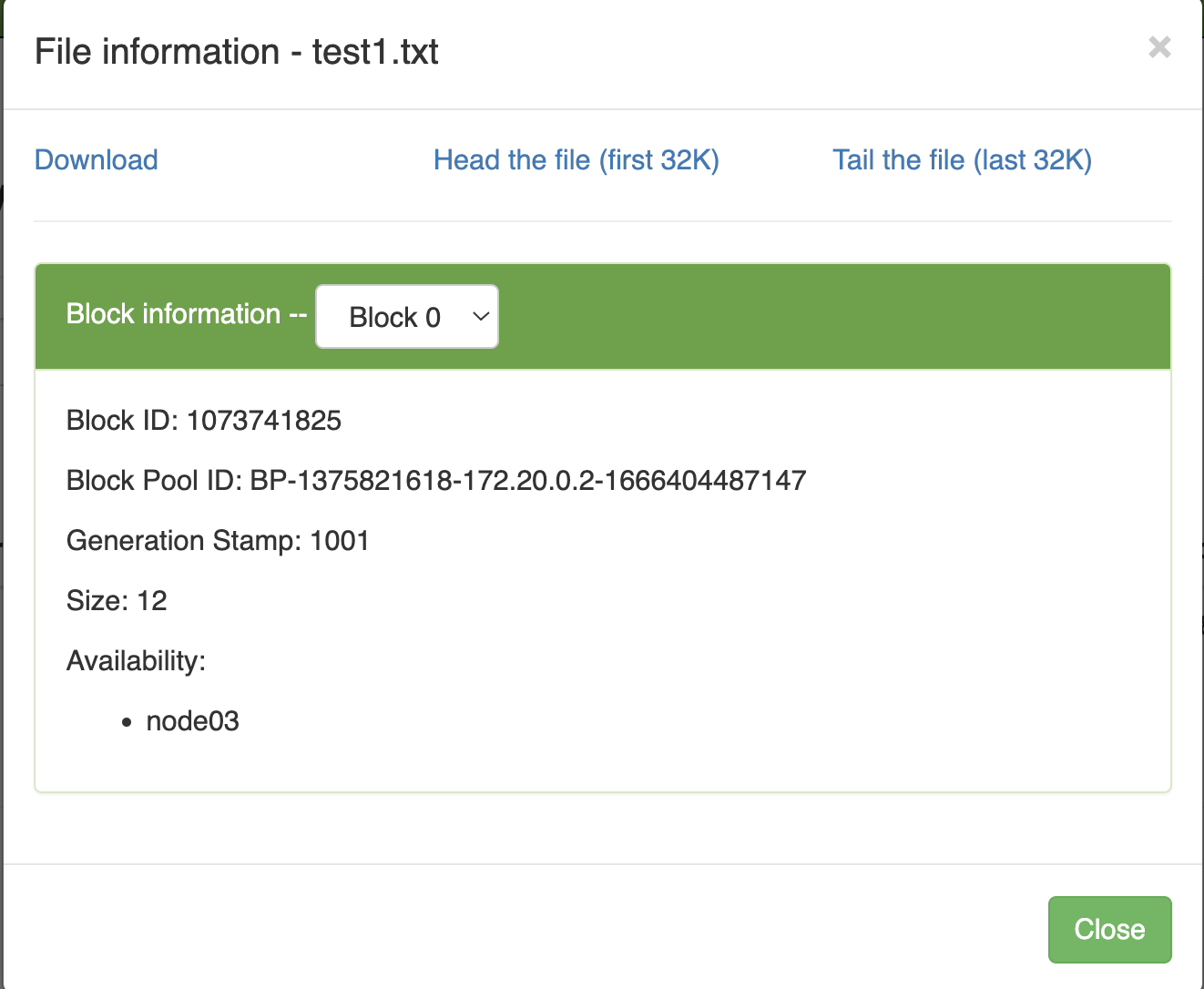
If we turn off Datanode on node03 now, we will no longer be able to access this file from node02.
hdfs@node03:~$ $HADOOP_HOME/bin/hdfs --daemon stop datanode
root@node02:~/install# hdfs dfs -copyToLocal /test1.txt ./
2022-10-22 12:36:57,139 WARN hdfs.DFSClient: No live nodes contain block BP-1375821618-172.20.0.2-1666404487147:blk_1073741825_1003 after checking nodes = [], ignoredNodes = null
- Write data from multiple nodes to the same file
hdfs@node02:~$ echo "data write from node2" > test2.txt
hdfs@node02:~$ hdfs dfs -appendToFile test2.txt /test1.txt
hdfs@node02:~$ hdfs dfs -cat /test1.txt
hello world
data write from node2
When checking the information, we see that the data is still only stored on 1 block of node03.
- Copy a data file larger than blocksize to HDFS
root@node01:~/install# hdfs dfs -copyFromLocal hadoop-3.3.4.tar.gz /hadoop.tar.gz
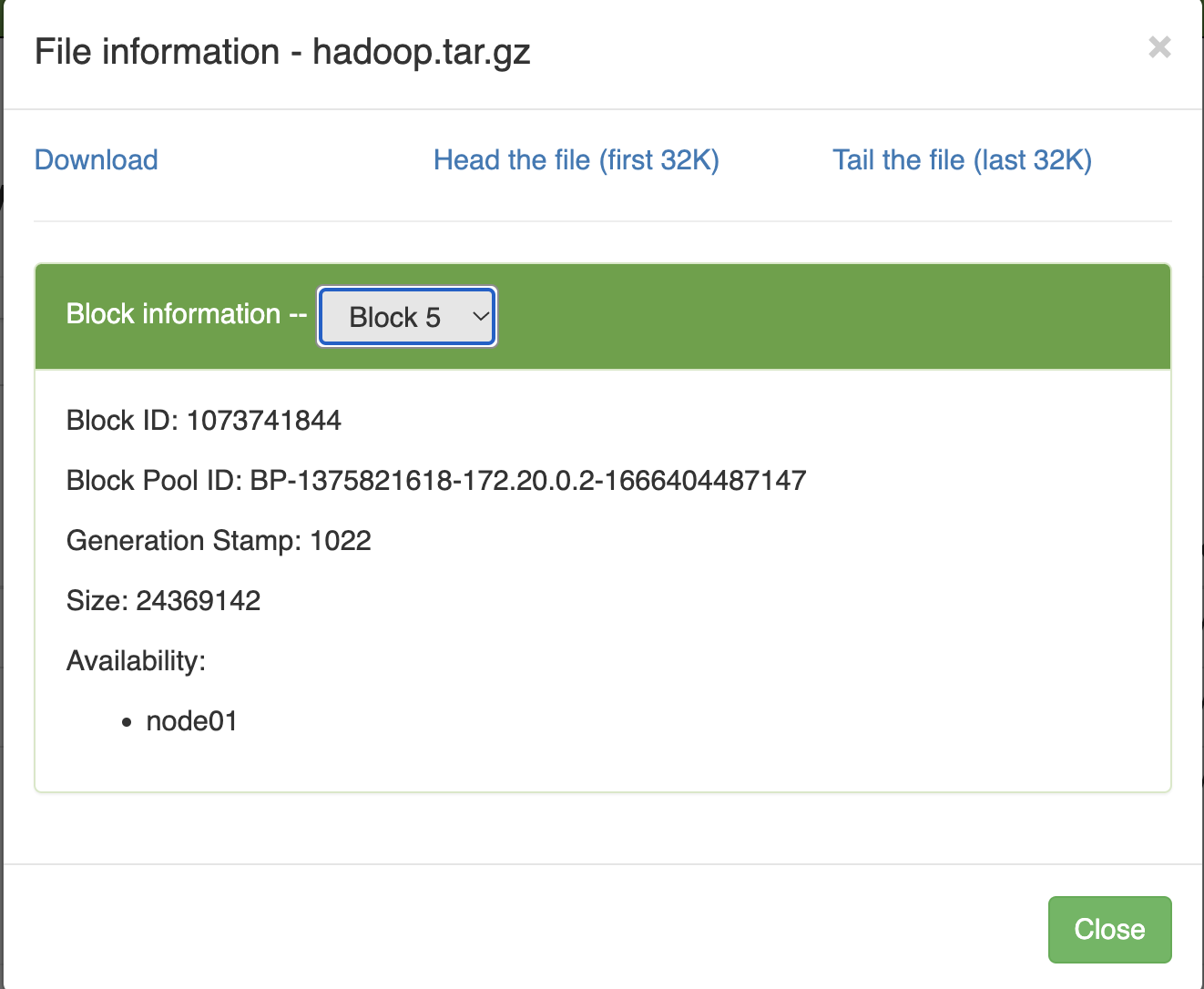
We see that all 5 blocks of this data file are stored on node01. If we want the data to be stored on multiple nodes to ensure safety, we need to change the replication number.
root@node03:~/install# hdfs dfs -D dfs.replication=2 -copyFromLocal hadoop-3.3.4.tar.gz /hadoop_2.tar.gz
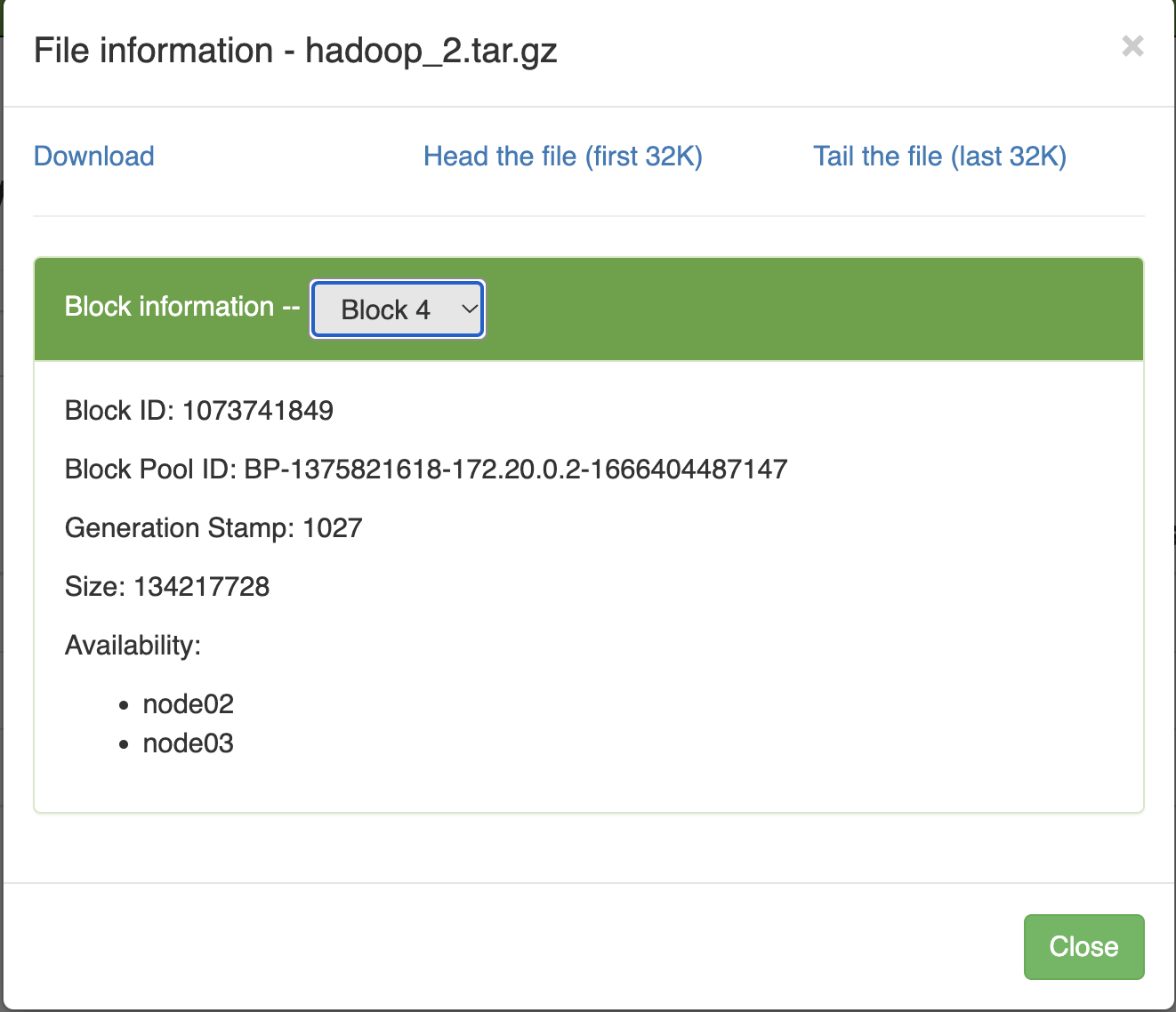
With replication number = 2, each block of the data file is stored on 2 nodes. At this time, if we turn off node03 and query the file from node02, we can still get the data.
root@node02:~/install# hdfs dfs -copyToLocal /hadoop_2.tar.gz ./
root@node02:~/install# ls
hadoop-3.3.4.tar.gz hadoop_2.tar.gz test
We continue to turn off node02 and try to query data from node01
root@node01:~/install# hdfs dfs -copyToLocal /hadoop_2.tar.gz ./
root@node01:~/install# ls
hadoop-3.3.4.tar.gz hadoop_2.tar.gz test
We can still get the data back, the reason is because the replication number of this data file is 2, so when node03 is turned off, Namenode will automatically create a new copy and save it on the remaining 2 nodes to ensure the replication number is still 2, thanks to that when node2 is turned off, we can still get all the data from node01.
- Test with Namenode turned off
node01
$HADOOP_HOME/bin/hdfs --daemon stop namenode
node02
hdfs@node02:~$ hdfs dfs -appendToFile test2.txt /test3.txt
appendToFile: Call From node02/172.20.0.3 to node01:9000 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
When Namenode is turned off, it will no longer be possible to read or write data, this is the weakness of the system with only 1 Namenode, in the following article I will introduce HA architecture with more than 1 Namenode.
- Test with all Datanodes turned off
node02
hdfs@node02:~$ hdfs dfs -copyFromLocal test2.txt /test4.txt
copyFromLocal: Cannot create file/test4.txt._COPYING_. Name node is in safe mode.
At this time, although it is still possible to connect to the Namenode, it is still impossible to read and write data on HDFS.
Conclusion
Through the tests we have performed, we can draw some of the following observations:
-
For the HDFS system to operate, it requires at least 1 Namenode and 1 Datanode, however, to meet the fault tolerance requirements, 2 Datanodes are needed and should have 2 Namenodes.
-
Data on HDFS is always prioritized for local storage instead of remote nodes. In case the Datanode on a node is not running, it will be transferred to another node for storage.
-
The replication number should be set to 2 or more so that when a node has a problem, it can still be restored from other nodes.
Through this article, I have introduced the most basic functions of HDFS and done some practical tests with it, hoping to be able to help you in the process of using it. See you in the next articles!

Lake Nguyen
Founder of Chainslake