Truy vấn dữ liệu trong Chainslake
- 6 minsTrong bài viết trước các bạn đã biết được khái quát về kiến trúc nền tảng của Chainslake platform, ở bài viết này chúng ta sẽ tìm hiểu cách tổ chức các bảng dữ liệu trong Chainslake và làm thế nào để truy vấn hiệu quả.
Nội dung
Viết truy vấn đầu tiên
Chainslake sử dụng SQL (Sequence Query Language) để truy vấn dữ liệu, nếu đây là lần đầu bạn biết đến ngôn ngữ SQL thì cũng không sao vì bên dưới mỗi câu truy vấn đều sẽ có giải thích chi tiết. VD:
select * from ethereum.transactions limit 10
- Câu truy vấn bắt đầu với từ khóa
selectdùng để yêu cầu các cột trong bảng, dấu*có nghĩa là lấy toàn bộ các cột của bảng- Từ khóa
fromdùng để xác định bảng cần lấy dữ liệu thông qua tên bảng, trong ví dụ này là bảngethereum.transactions.- Từ khóa
limitdùng để giới hạn số hàng (bản ghi) trả về trong kết quả.- Ý nghĩa của câu truy vấn trên là trả về 10 bản ghi trong bảng
ethereum.transactions
Bạn hãy click vào hình ảnh dưới đây để đi đến trang Metabase của Chainslake (bạn sẽ cần login hoặc đăng ký tài khoản). Click vào nút Run query (hoặc Ctrl + Enter) để thực thi câu truy vấn này.
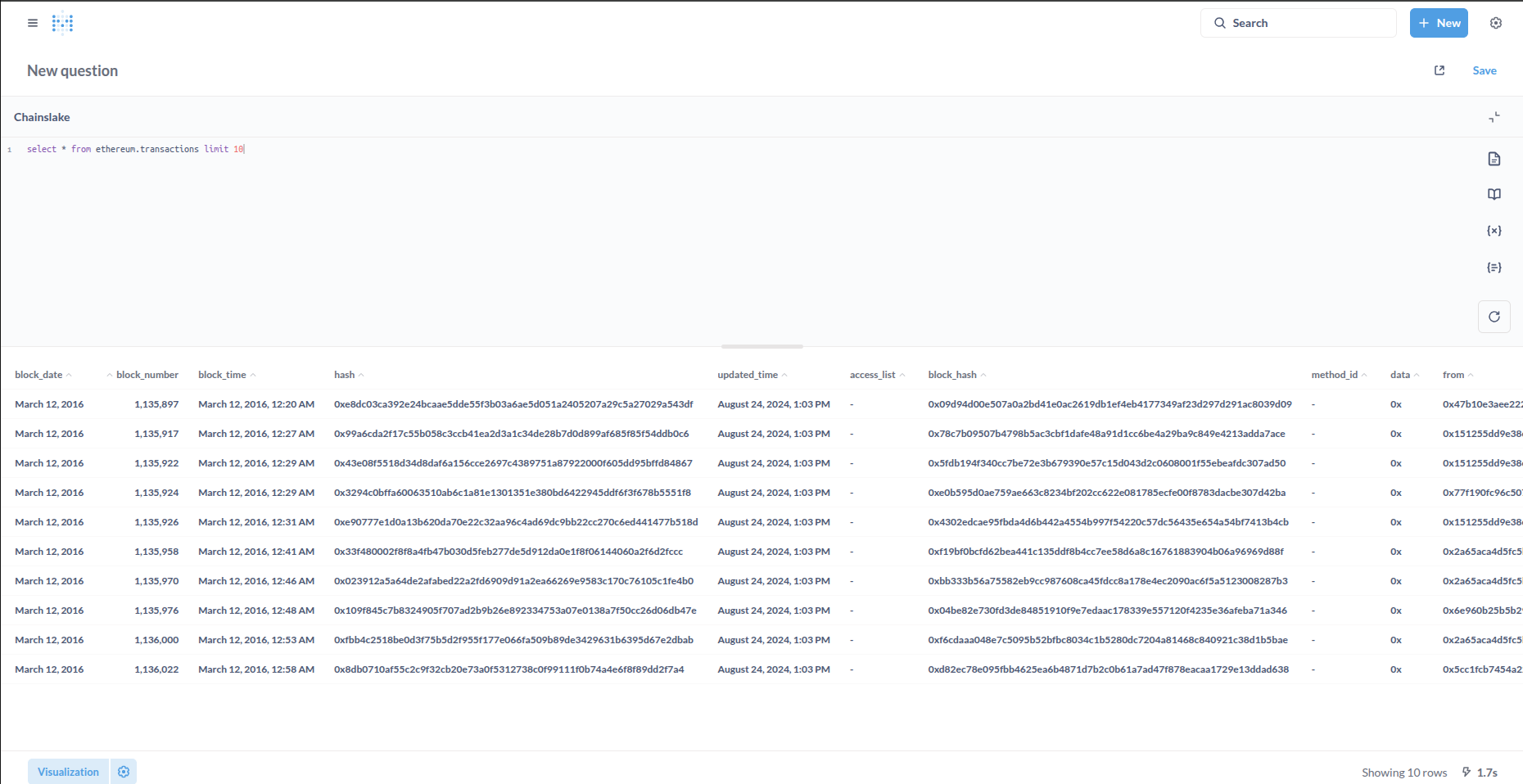
Lưu ý: Tên bảng của Chainslake bao gồm phần thư mục và phần tên phân tách bởi dấu .. Bạn có thể bắt đầu khám phá các bảng dữ liệu của Chainslake tại đây.
Tips: Bạn có thể xem các truy vấn được chia sẻ bởi những người dùng khác trên trang cá nhân của họ hoặc tại đây bằng cách click vào các biểu đồ để đi đến trang Metabase, chọn OPEN EDITOR để xem truy vấn.
Tổ chức bảng dữ liệu
Các bảng dữ liệu được sắp xếp trong thư mục theo ý nghĩa của chúng, mỗi bảng là kết quả của 1 phép biến đổi dữ liệu từ 1 hoặc nhiều bảng trước đó. Như đã chia sẻ trong bài viết trước, dữ liệu lấy từ các blockchain node sau khi đi qua các bước biến đổi bao gồm giải mã, lọc, tổng hợp sẽ thu được dữ liệu tinh (insight data).
Để hiểu rõ hơn, mình sẽ lấy một ví dụ về bảng bitcoin_balances.utxo_latest_day, bảng này được xây dựng để dễ dàng tính toán số dư của 1 ví bitcoin bất kỳ.
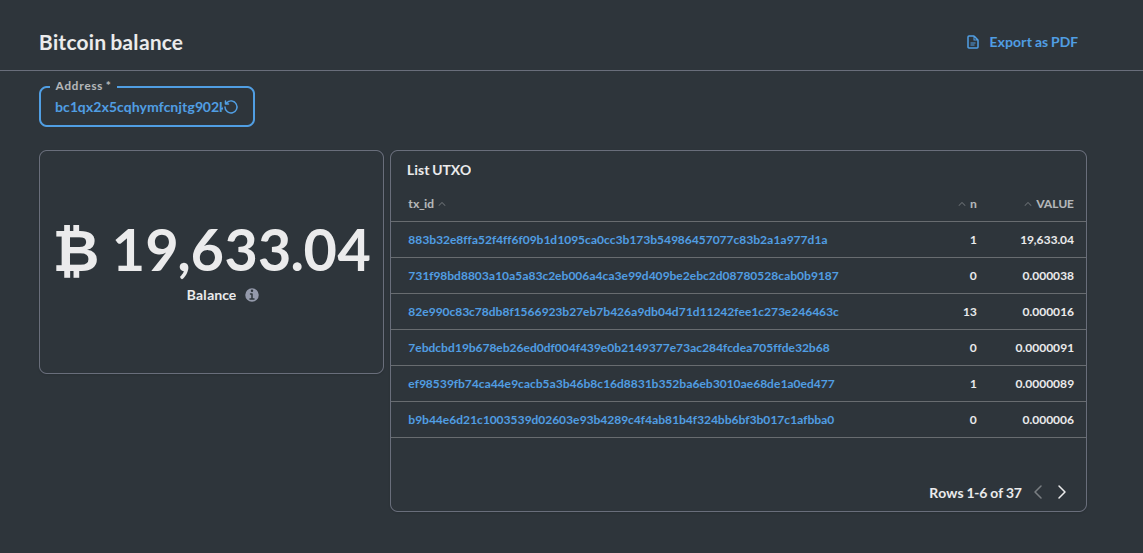
Trước hết mình sẽ giải thích qua về khái niệm UTXO (Unspent Transaction Output) trong Bitcoin:
- UTXO có thể hiểu đơn giản là 1 phần tiền chưa được tiêu (giống một tờ tiền trong ví), mỗi UTXO có giá trị riêng đại diện cho số lượng bitcoin mà nó nắm giữ, như vậy số dư của 1 ví sẽ bằng tổng giá trị của tất cả các UTXO có trong ví đó.
- 1 UTXO không thể bị chia nhỏ (giống như không thể cắt nhỏ tờ tiền ra vậy), khi thực hiện giao dịch, ví sẽ gửi UTXO và nhận lại phần thừa trong 1 UTXO mới.
- 1 UTXO được xác định duy nhất bằng transaction id (tx_id) và số thứ tự (n) của UTXO trong giao dịch.
Quay lại với bảng bitcoin_balances.utxo_latest_day, bảng này chứa thông tin UTXO của tất cả các ví Bitcoin cho đến 0h ngày hiện tại. Các column của nó bao gồm:
- address: địa chỉ ví Bitcoin chứa UTXO
- tx_id: id transaction của UTXO
- n: Số thứ tự của UTXO trong transaction
- value: Số lượng Bitcoin trong UTXO
Sơ đồ luồng dữ liệu để xây dựng bảng bitcoin_balances.utxo_latest_day như sau:
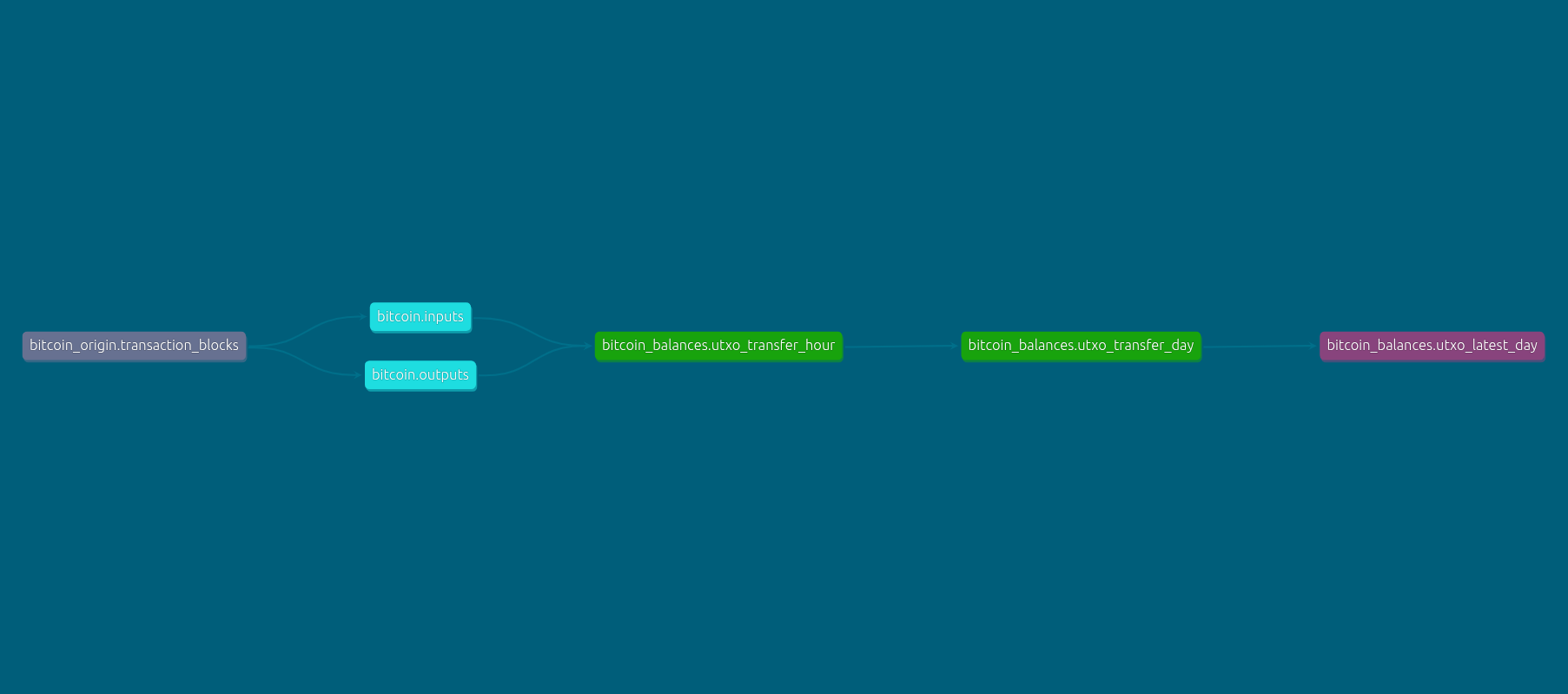
- Từ bảng
bitcoin_origin.transaction_blocks(bảng chứa dữ liệu gốc được lấy từ Bitcoin node) extract ra 2 bảngbitcoin.inputs,bitcoin.outputschứa các UTXO đầu vào và đầu ra của mỗi giao dịch. bitcoin_balances.utxo_transfer_hour: tổng hợp các input và output UTXO theo từng giờbitcoin_balances.utxo_transfer_day: tổng hợp các input và output UTXO theo ngàybitcoin_balances.utxo_latest_day: tổng hợp input và output UTXO đến ngày cuối cùng (tổng hợp từ tất cả các ngày trước đó)
Tip: trên trang data.chainslake.com, mỗi bảng bạn không chỉ xem được mô tả, các column của bảng, mà còn có thể xem được source code tạo nên bảng đó.
Cách truy vấn hiệu quả
Do chứa toàn bộ lịch sử giao dịch Blockchain nên các bảng dữ liệu của Chainslake đều có số lượng bản ghi rất lớn, tuy nhiên các bảng đều đã được partition và đánh index hợp lý theo ngày và thời gian do đó mình có một số lưu ý dành cho các bạn khi viết truy vấn như sau:
- Sử dụng lọc dữ liệu theo
block_datehoặcblock_number,block_timesớm nhất có thể để giảm thiểu lượng dữ liệu cần scan trong câu truy vấn. - Khi cần join các bảng, hãy luôn bổ sung thêm điều kiện join có các column được partition hoặc có index. VD: khi join 2 bảng theo điều kiện join là tx_hash, hãy bổ sung thêm điều kiện join theo block_date, block_number, hoặc block_time, điều này không làm sai logic câu truy vấn (do giao dịch cùng tx_hash sẽ cùng ngày, cùng số block và cùng thời gian) nhưng lại khiến câu truy vấn chạy nhanh nhiều so với chỉ sử dụng điều kiện join trên tx_hash (do tx_hash không có index).
- Luôn ưu tiên sử dụng các bảng nằm ở cuối luồng dữ liệu (các bảng insight data) thay vì tổng hợp lại từ các bảng nguồn.
Kết luận
Trong bài viết này mình hi vọng đã giúp các bạn hiểu hơn về cách thức tổ chức và truy vấn dữ liệu của Chainslake. Trong bài viết tiếp theo chúng ta sẽ tìm hiểu về dữ liệu của Ethereum cũng như tất cả các EVM blockchain. Hẹn gặp lại!