Spark guidelines for beginer
- 8 minsIn the previous article, I introduced you to the MapReduce computational model that allows processing large amounts of data stored on many computers. However, the MapReduce model has a disadvantage that it has to continuously read and write data from the hard drive, which makes the MapReduce program slow. To solve this problem, Spark was born based on the idea that: data only needs to be read once from the input and written once to the output, during the processing of intermediate data will be in memory instead of having to continuously read and write from the hard drive, thereby significantly improving performance compared to MapReduce. Experiments show that Spark can process up to 100 times faster than MapReduce.
Contents
- Overview
- Setting up a development environment
- Getting started with Spark
- Running a Spark program on a Hadoop cluster
- Conclusion
I am currently consulting, designing and implementing data analysis infrastructure, Data Warehouse, Lakehouse for individuals and organizations in need. You can see and try a system I have built here. Please contact me via email: lakechain.nguyen@gmail.com. Thank you!
Overview
Spark is a general-purpose, fast, and distributed computing engine that can process huge amounts of data in parallel and distributed across multiple computers simultaneously. Below is a diagram describing the operation of a Spark application when running on a cluster of computers:
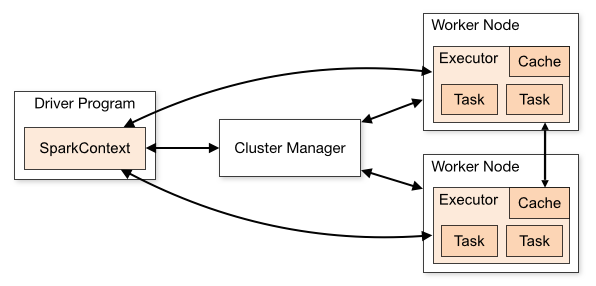
- Driver Program: The driver is the main process (main) running on the Master node that is responsible for controlling, scheduling, and coordinating work in the entire program. It is the process that is initiated first and terminated last.
- Spark context: An object initialized by the Driver program located on the master node, storing all information about data structure, configuration, connection to Cluster manager.
- Cluster Manager: Manages and coordinates resources in the cluster, Spark context can work with many different types of Cluster managers such as Standalone, Apache Mesos, Hadoop YARN, Kubernetes.
- Executor: Processes running on Worker nodes, receiving and processing tasks from the Driver.
Similar to MapReduce, the Spark program will be sent to the nodes that have data, one node will be selected as the master to run the driver process, the other nodes will be workers. The Driver creates tasks and divides them among the workers according to the local processing principle, that is, data on which node will be processed by the executor on that node. To increase processing efficiency, data will be uploaded and maintained in the memory of workers in a data structure called Resilient Distributed Dataset (RDD) with the following characteristics:
-
Distributed: RDD is a
CollectionofElements, divided intoPartitionsand distributed across the nodes of the cluster, thereby allowing data in the RDD to be processed in parallel. - Read only: RDD can only be created from Input data or from another RDD and cannot be changed after creation.
- Persist: Spark maintains RDDs in memory throughout the run, allowing them to be reused multiple times.
- Fault tolerance: Finally, RDD also has the ability to self-repair when a node fails thanks to the reconstruction mechanism from Input data or from other RDDs.
RDD provides 2 types of Operations: transformations and actions:
- Transformations: Are groups of Operations that create a new RDD from an existing RDD, for example: map, flatMap, filter, mapPartition, reduceByKey, groupByKey…
- Actions: are groups of Operations that need to return data to the Driver after performing calculations on the RDD, for example: reduce, collect, count and save functions…
All Transformations are lazy, they will not process data when called, only when an Action is called and the result of a Transformation is needed, then the Transformation will perform the calculation. This design makes Spark run more efficiently because it does not have to store too much unused intermediate data in memory. After each Actions call, the intermediate data is also released from memory, if the user wants to keep it for use in the next Actions, they can use the persist or cache method.
Along with RDD, Spark also provides Dataframe and Dataset, which are both distributed data structures. In Dataframe, data is organized into column names similar to tables in a database, while in Dataset, each element is a JVM type-safe Object, so it is very convenient to handle structured data.
Install the development environment
That’s the basics, now let’s get started with the installation and test coding!
- First, download the latest version of Spark here
- Next, unzip and copy to the installation directory on your computer (on my computer, it is the
~/Installfolder)$ tar -xzvf spark-3.1.2-bin-hadoop3.2.tgz $ mv spark-3.1.2-bin-hadoop3.2 ~/Install/spark - Add environment variables
export SPARK_HOME=~/Install/spark export PATH=$PATH:$SPARK_HOME/bin - Reload environment variables
$ source ~/.bash_profile -
You also need to install Java and Scala. Note that you need to choose the Java and Scala versions that are suitable for Spark, here I choose Java 11 and Scala 2.12
- Check if Spark has been installed successfully using
spark-shell
$ spark-shell
Spark context Web UI available at http://localhost:4041
Spark context available as 'sc' (master = local[*], app id = local-1676799060327).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.15 (OpenJDK 64-Bit Server VM, Java 11.0.17)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
Example starting with Spark
With Spark, I use Scala language with IDE Intellij. For convenience, I have created a sample Spark project here you can clone or fork. In this project, there are some notes as follows:
-
I have written the build and run method in the
Readme.mdfile. - To create a new Job, you need to create a
Scalaobject in thejobpackage and extendJobInf, put the logic processing code in therunmethod, declare the job name inJobFactory(see the example of theDemojob). - To run a new job on dev you need to create a folder named job in the
run/devfolder, in the folder there are 2 filesapplication.propertiesandrun.sh.application.propertieswill contain configuration parameters for the job and requiresapp_nameso thatJobFactorycan initialize the correct Job.run.shcontains the command to executespark-submit:
spark-submit --class Main \
--master local[*] \ # configure cluster manager
--deploy-mode client \ # Configure deployment: client (driver located on current node) or cluster (driver located on any node of the cluster)
--driver-memory 2g \ # Configure ram for driver
--executor-memory 2g \ # Configure ram for executor
--executor-cores 2 \ # Configure number of cores (threads) for executor
--num-executors 1 \ # Configure number of executors
--conf spark.dynamicAllocation.enabled=false \
--conf spark.scheduler.mode=FAIR \
--packages org.web3j:abi:4.5.10,org.postgresql:postgresql:42.5.0 \ # Configure additional libraries
--files ./application.properties \
../spark_template_dev.jar \
application.properties &
- To install additional libraries for Dev, you need to add the library to the
libraryDependenciesvariable in thebuild.sbtfile, you can find the library and its version here.
Run Spark program on Hadoop cluster
First, you need to install Spark on Hadoop cluster according to the instructions here. Note that because Spark will use Yarn as Cluster Manager, you only need to install Spark on 1 node and will execute spark jobs on that node.
Next, you pull the code from git to the node where Spark is installed and run the job in the run/product directory, note that you need to edit the --master configuration in the run.sh file from local[*] to yarn.
When a Spark application is running, we can monitor it on the Spark UI interface
Conclusion
Today’s article will stop at introducing the most basic concepts and knowledge about Spark along with initial instructions for installing and getting acquainted with this framework. In the following articles, I will go deeper into the content related to Spark programming, using modules such as Spark Sql, Spark Streaming… See you again in the next articles!

Lake Nguyen
Founder of Chainslake