Query data in Chainslake
- 5 minsIn the previous article you learned about the basic architecture of Chainslake platform. In this article we will learn how to organize data tables in Chainslake and how to query effectively.
Content
Write your first query
Chainslake uses SQL (Sequence Query Language) to query data. If this is your first time learning SQL, it’s okay because each query will have a detailed explanation below. For example:
select * from ethereum.transactions limit 10
- The query starts with the keyword
selectto request columns in the table, the*sign means to get all columns of the table- The keyword
fromis used to identify the table to get data through the table name, in this example it is the tableethereum.transactions.- The keyword
limitis used to limit the number of rows (records) returned in the result.- The meaning of the above query is to return 10 records in the table
ethereum.transactions
Click on the image below to go to Chainslake’s Metabase page (you will need to login or register for an account). Click the Run query button (or Ctrl + Enter) to execute this query.
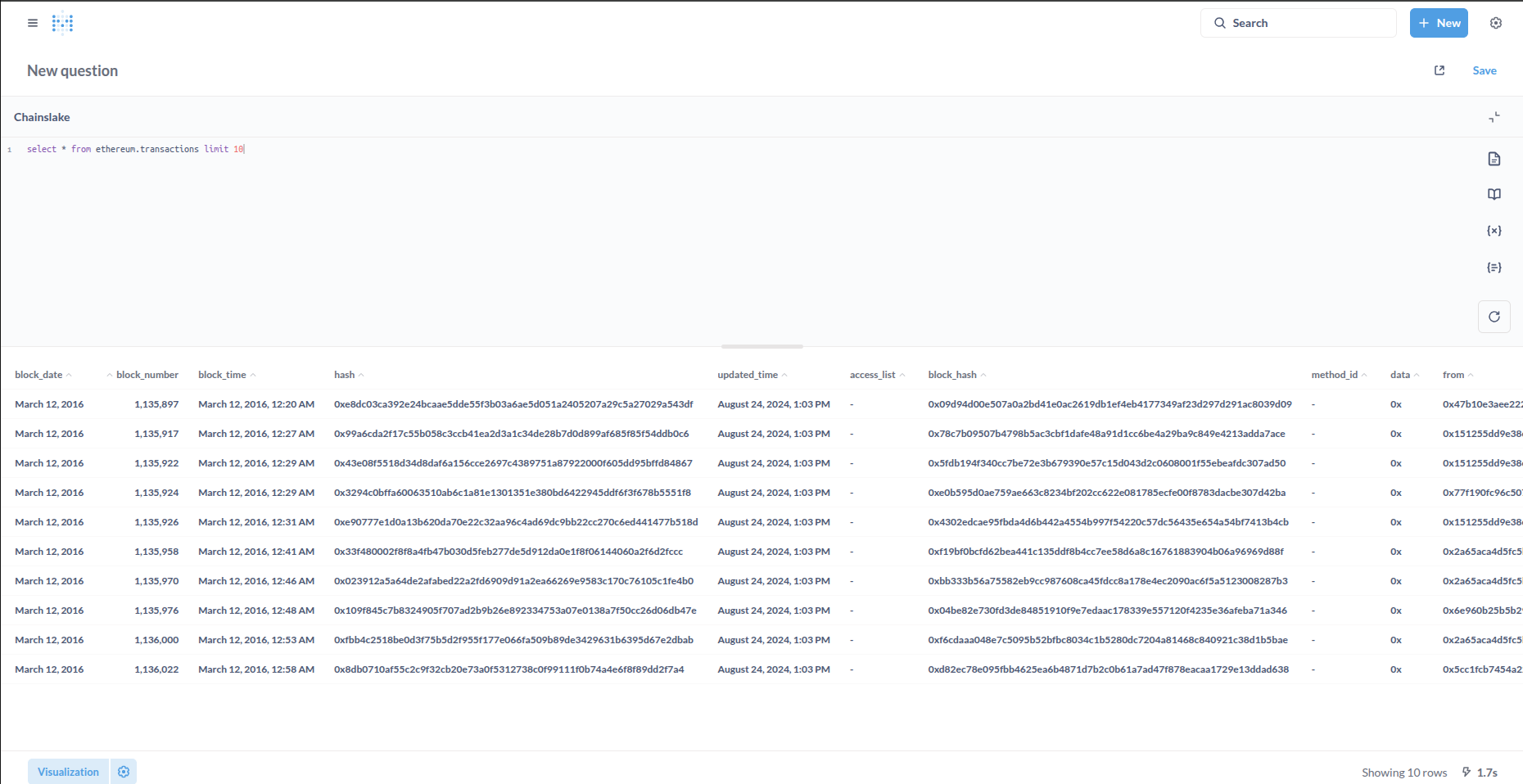
Note: Chainslake table names consist of a directory and a name separated by a .. You can start exploring Chainslake’s data tables here.
Tips: You can view queries shared by other users on their personal pages or here by clicking on the charts to go to the Metabase page, select OPEN EDITOR to view the queries.
Data governance
The data tables are arranged in folders according to their meaning, each table is the result of a data transformation from one or more previous tables. As shared in the previous article, the data taken from the blockchain nodes after going through the transformation steps including decoding, filtering, and aggreating will obtain insight data.
To understand better, I will take an example of the table bitcoin_balances.utxo_latest_day, this table is built to easily calculate the balance of any bitcoin wallet.
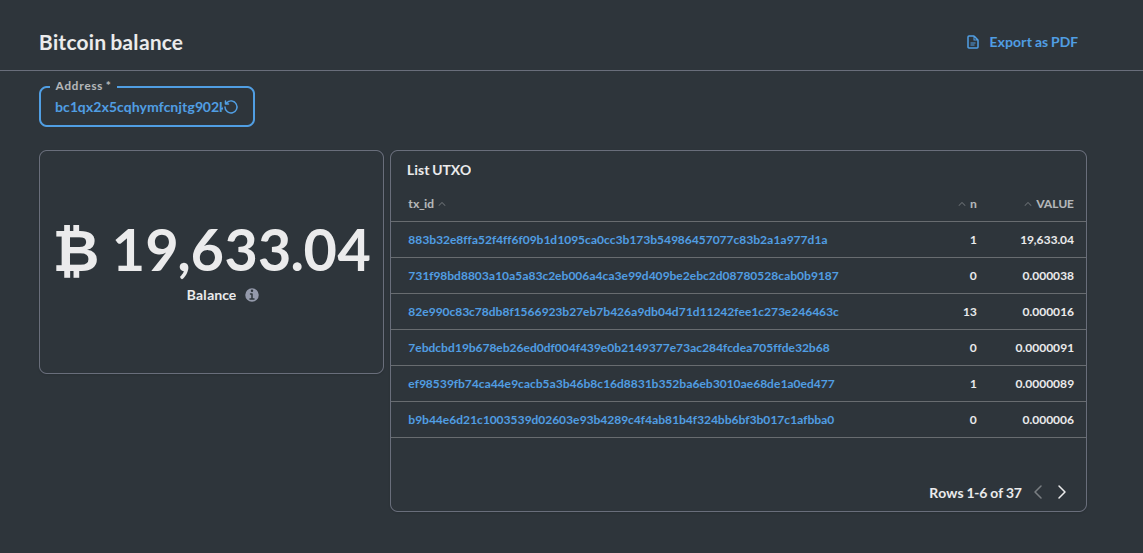
First of all, I will briefly explain the concept of UTXO (Unspent Transaction Output) in Bitcoin:
- UTXO can be simply understood as a part of money that has not been spent (like a bill in a wallet), each UTXO has its own value representing the amount of bitcoin it holds, so the balance of a wallet will be equal to the total value of all UTXOs in that wallet.
- 1 UTXO cannot be divided (like a bill cannot be cut into small pieces), when making a transaction, the wallet will send the UTXO and receive the remaining part in a new UTXO.
- 1 UTXO is uniquely identified by the transaction id (tx_id) and the serial number (n) of the UTXO in the transaction.
Back to the bitcoin_balances.utxo_latest_day table, this table contains the UTXO information of all Bitcoin wallets until 0:00 on the current day. Its columns include:
- address: Bitcoin wallet address containing the UTXO
- tx_id: transaction id of the UTXO
- n: Serial number of the UTXO in the transaction
- value: Amount of Bitcoin in the UTXO
The data flow diagram for constructing the bitcoin_balances.utxo_latest_day table is as follows:
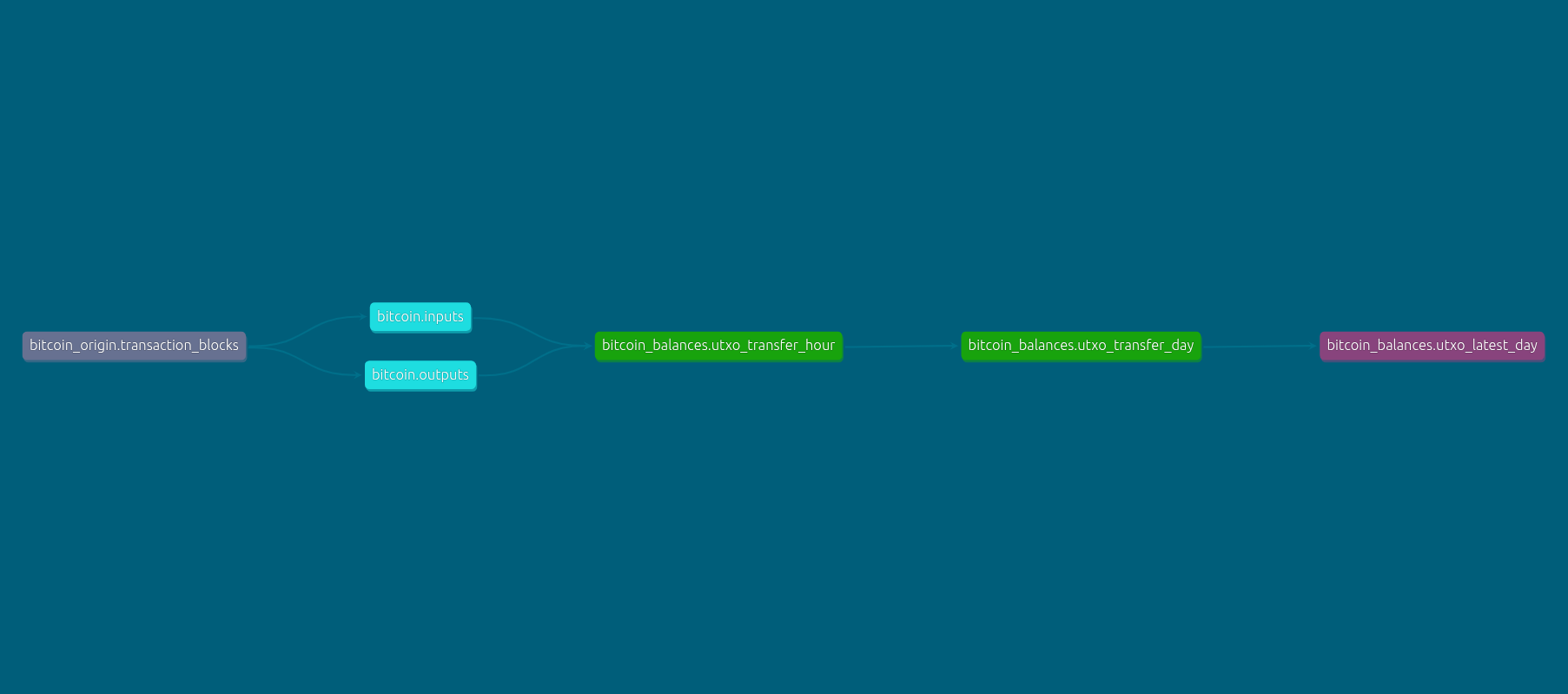
- From the table
bitcoin_origin.transaction_blocks(the table containing the original data taken from the Bitcoin node), extract 2 tablesbitcoin.inputsandbitcoin.outputscontaining the input and output UTXOs of each transaction. bitcoin_balances.utxo_transfer_hour: aggregates the input and output UTXOs by hourbitcoin_balances.utxo_transfer_day: aggregates the input and output UTXOs by daybitcoin_balances.utxo_latest_day: aggregates the input and output UTXOs up to the last day (aggregates from all previous days)
Tip: on the page data.chainslake.com, for each table you can not only see the description and columns of the table, but also see the source code that creates that table.
How to write the queries effectively
Because it contains the entire Blockchain transaction history, Chainslake’s data tables all have a very large number of records, but the tables have been partitioned and indexed reasonably by date and time, so I have some notes for you when writing queries as follows:
- Use data filtering by
block_dateorblock_number,block_timeas soon as possible to minimize the amount of data that needs to be scanned in the query. - When you need to join tables, always add join conditions with columns that are partitioned or have indexes. For example, when joining 2 tables with the join condition being tx_hash, add join conditions according to block_date, block_number, or block_time, this does not change the query logic (because transactions with the same tx_hash will be on the same day, same block number and same time) but makes the query run much faster than just using the join condition on tx_hash (because tx_hash does not have an index).
- Always prioritize using tables at the end of the data flow diagram (insight data tables) instead of aggregating from source tables.
Conclusion
In this article, I hope to help you better understand how Chainslake organizes and queries data. In the next article, we will learn about Ethereum data as well as all EVM blockchains. See you again!