Optimize Data Warehouse
- 7 minsIn a previous article, I shared with you the similarities and differences between Database and Data warehouse, you can review here. Just like optimizing Database, optimizing Data warehouse is also an extremely important job, determining the performance of the entire system. However, due to the differences in function and design between these two systems, optimizing Data warehouse is also very different from Database. In this article, I will share with you some optimization techniques that I am applying to the product Chainslake, hopefully these will be good suggestions to apply to your system.
Content
- Why do we need to optimize Data warehouse?
- Data warehouse optimization method
- Data partition
- Building intermediate tables
- Optimize queries
- Conclusion
I am currently consulting, designing and implementing data analysis infrastructure, Data Warehouse, Lakehouse for individuals and organizations in need. You can see and try a system I have built here. Please contact me via email: lakechain.nguyen@gmail.com. Thank you!
Why do we need to optimize data warehouse?
Similar to Database, an unoptimized Data warehouse will lead to queries taking a long time to run, costing a lot of computation, and may not even be executed. If in Database we can optimize by rewriting better queries, using more indexes, however with Data warehouse things are not that simple for the following reasons:
- Data in Data warehouse is often large in size, the number of records in the table is much larger than in the database.
-
The amount of newly added data will continuously increase over time, this is due to the characteristics of Data warehouse data being historical data, recording changes or events, logs… Meanwhile in Database, the size of the table will only increase to a certain amount and then remain stable or increase slightly, at this time rewriting queries and indexing on the database will be effective.
- Database serves daily operations, so it can be easily optimized or indexed to optimize for certain queries. Data warehouse serves data analysis, so the number of queries is very large and diverse, every query needs to be optimized, so indexing for optimization is not feasible.
For these reasons, optimizing Data warehouse needs to be carefully considered right from the design and data organization stage, not waiting until the data has been poured in and swelled up a lot before looking for ways to optimize, then it is likely to be too late ![]() .
.
Data warehouse optimization method
The general method for optimization for both Database and Data warehouse is to reduce the number of records that need to be scanned when performing queries. I will take an example as follows:
SELECT tx_hash FROM ethereum.transactions
WHERE block_date = date '2024-12-15';
Normally, to execute this query, the Database or Data warehouse will have to scan the entire ethereum.transactions table (currently containing 2.6B records) to find all tx_hash on 12/15/2024, which is of course time-consuming and not optimal.
For the Database, we can think about indexing the block_date column of the ethereum.transactions table, however, with the number of records up to 2.6B, indexing will also take a lot of time. In addition, with the amount of data being added continuously, using indexes will make adding data slower.
On Data warehouse there are specific techniques for optimization, I will introduce some methods that I am using for Chainslake product
Data partition
Data partition (Partition) is to organize data in a table into many files of reasonable size according to one or a few columns.
For example: Realizing that the data in the transactions table is always loaded in chronological order, I partitioned this table according to block_date, the data in 1 day is also divided into many smaller files, each file contains data in a period of time, arranged and not overlapping. This can be done by repartitioning before writing data to the table:
val outputDf = ...
outputDf.repartitionByRange(col("block_date"), col("block_time"))
.write.format("delta")
.mode(SaveMode.Append)
.option("spark.sql.files.maxRecordsPerFile", 1000)
.partitionBy("block_date")
.saveAsTable("output_table")
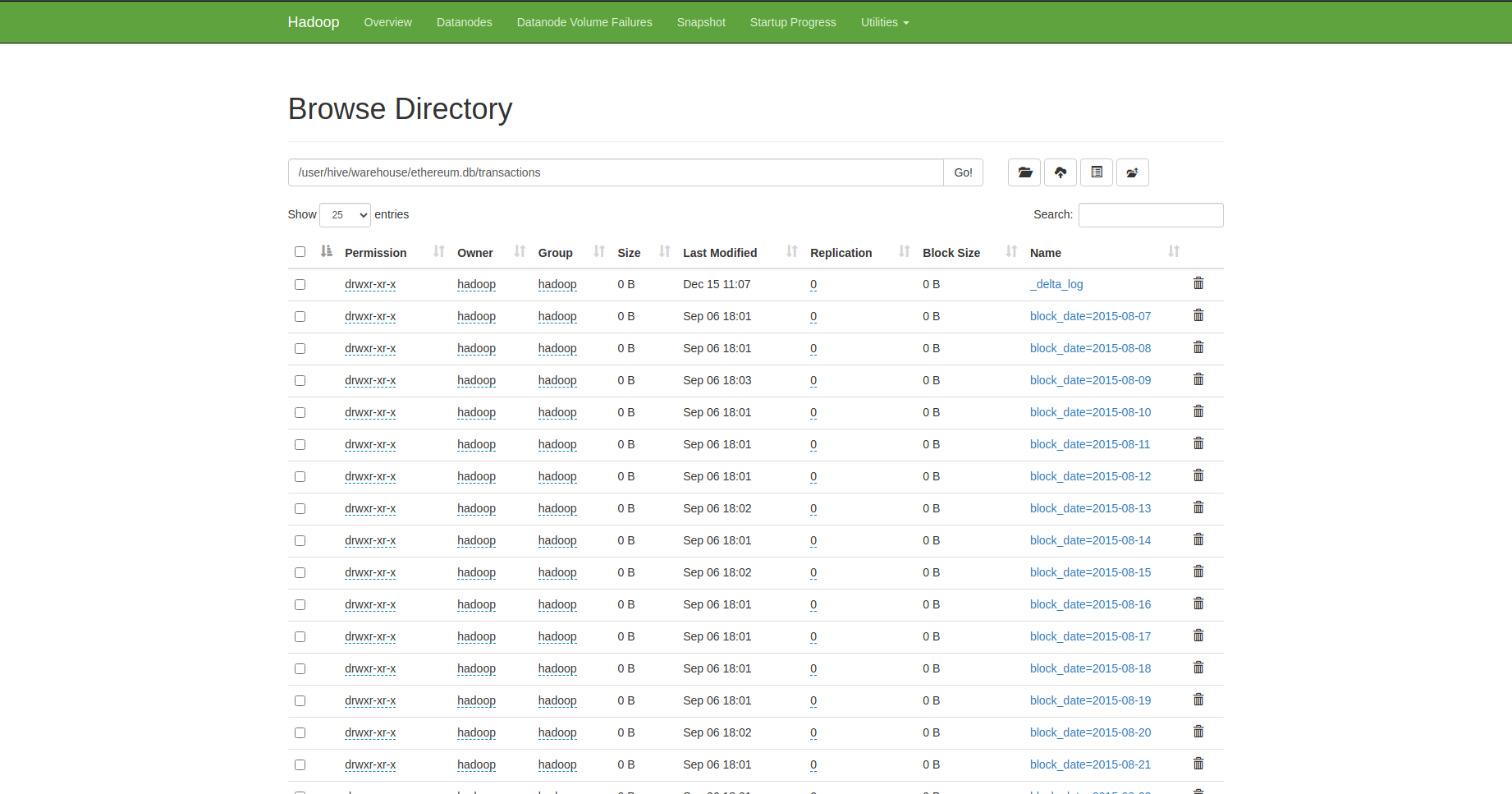
Since my tables use the Delta format, each partition (corresponding to 1 data file) will be managed by the Delta file system and data statistics will be collected. This information will then be used by the Trino query engine, allowing it to ignore files that do not contain the necessary data when executing queries.
Advantages: This is a simple, easy-to-implement method, does not incur additional data storage costs but can be very effective, especially for queries that need to filter or join based on partitioned columns.
Disadvantages: In a table, partitioning can only be performed on 1 or a few related columns such as block_date, block_time, block_number, and cannot be performed on columns with many differences such as block_date with tx_hash.
Experience: Each partition should have a moderate size, too large or too small is not good (can be adjusted by configuring spark.sql.files.maxRecordsPerFile).
Build an intermediate table
Intermediate data tables are data tables that are combined and aggregated from the original raw data tables, they are often much smaller in size, which makes queries on the intermediate table simpler and faster than when performing on the raw data tables.
For example: To know which tokens a wallet has transferred and received in any given day, and how many, instead of performing queries on the ethereum_decoded.erc20_evt_transfer table, I built an intermediate table ethereum_balances.erc20_transfer_day to aggregate the daily balance changes of all tokens of all wallets. From there, queries on the ethereum_balances.erc20_transfer_day table are much faster than the original transfer table. At the same time, from the transfer day table, I can synthesize the ethereum_balances.er20_native table containing the final balance of all wallets more easily.
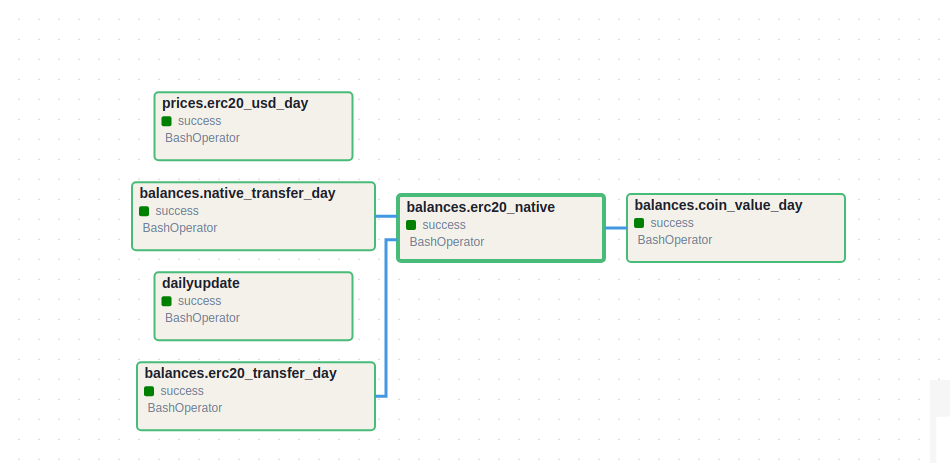
Advantages: Significantly improve query efficiency, especially when combined with partitions. Reduce the complexity of writing queries, making queries easier to read and understand.
Disadvantages: It takes more space to store the intermediate table, and costs computation to maintain data updates for the intermediate table.
Experience: Consider carefully before building a new intermediate table, only do it if it is really necessary and effective to optimize many important queries.
Optimizing queries
Partitioning or building intermediate tables will be meaningless if the query is not written to use them. So here are some notes when writing queries:
- Always use filters or join tables by partitioned columns whenever possible, as early as possible because filtering out unnecessary data early will help improve query performance a lot.
For example: If you need to join 2 tablesethereum.transactionsandethereum.logsby columntx_hashon 15/12/2024, filter data on both tables on 15/12/2024 first and then join bytx_hash. - Prioritize using existing intermediate tables before thinking about querying raw data tables.
For example, instead of calculating the balance of a wallet by filtering and aggregating from theethereum_decoded.erc20_evt_transfertable, use theethereum_balances.erc20_nativetable, even if the balances table only shows the balance of the wallet until the end of yesterday, using this result combined with the filtered transfer data only for today will run much faster.
Conclusion
In this article, I introduced to you some Data warehouse optimization techniques that I used when building Chainslake, hope it can help you. See you in the next articles!

Lake Nguyen
Founder of Chainslake