Introduce Chainslake - Blockchain Lakehouse Framework
- 5 minsHi everyone, I’m Lake Nguyen, founder of Chainslake - a lakehouse framework for blockchain and crypto. Chainslake provides technology solutions for customers, helping them build and operate blockchain lakehouses for many purposes such as querying, tracing transactions, monitoring, alerting, analyzing, predicting trends from data or using data to train AI models… Chainslake has a demo page for customers to experience for free at chainslake.com and some demo channels analyzing by chain and protocol:
- chainslake.com/@bitcoin
- chainslake.com/@ethereum
- chainslake.com/@binance
- chainslake.com/@aave
- chainslake.com/@nftfi
- chainslake.com/@opensea
- chainslake.com/@uniswap
Chainslake gives customers control over their systems and data, ensuring privacy and security for customers, while optimizing infrastructure costs according to their needs. However, this also requires customers to have certain understanding of system design and operation to be able to use the framework effectively. Therefore, in parallel with developing and perfecting the framework, I will write this blog to share knowledge and experience in using the framework, and I look forward to receiving support from readers.
In this first article, I will introduce an overview and design the overall architecture of the framework.
Content
Overview
If you are interested in the blockchain and crypto field, you probably know that blockchain data (Onchain data) is shared publicly (due to the decentralized nature of Blockchain). This allows anyone to access and use this Onchain data. However, blockchain data (usually transaction data) is packaged in blocks, using special data structures to optimize transaction authentication but making it difficult to retrieve and analyze this data, which has promoted the emergence of blockchain data analysis products.
In essence, all blockchain analysis products are a combination of Onchain data and Offchain knowledge (including Offchain data, coordination methods, analysis, presentation… or any other private data). It is the Offchain part that makes the difference between these products. If you are looking to build your own blockchain analytics product or simply want to ensure privacy for your Offchain part, you can consider using Chainslake.
Chainslake is an analytics tool that allows you to build and operate a private data platform, where you can freely combine Onchain data with your Offchain data without worrying about the risk of data leakage, thereby being able to develop your own analytics product.
For a data analytics product, especially with big data like Blockchain, the issue of cost optimization always needs special attention, understanding this, Chainslake is designed to be lean but still easy to scale according to demand, thereby helping to save costs. In terms of deployment, Chainslake has 2 options: On-premise on physical servers or On-cloud on AWS.
Architecture design
Data flow
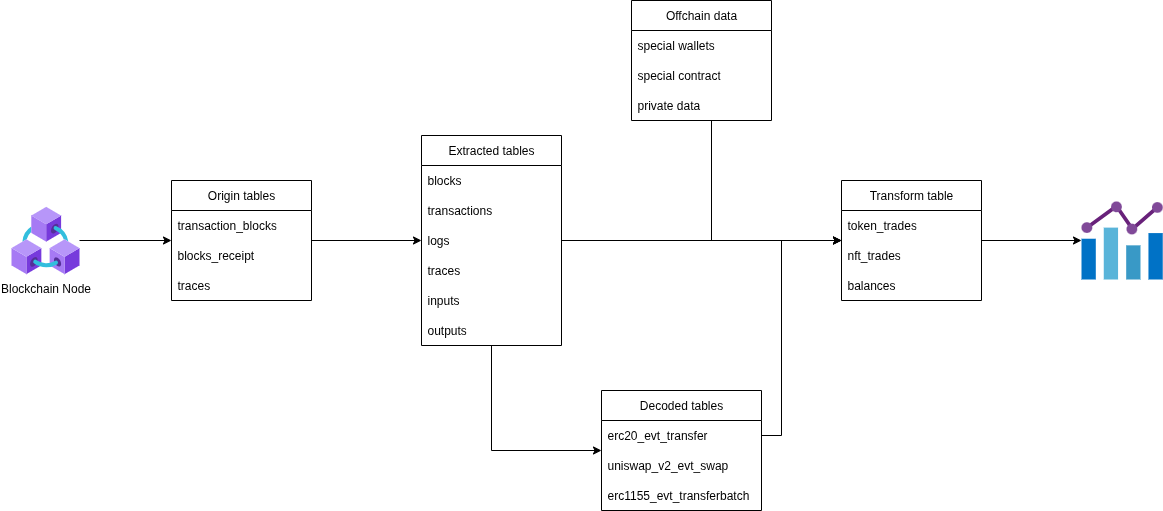
In general, Chainslake’s data flow is built as follows:
- Starting with data taken from Blockchain nodes (Onchain), raw data is then stored intact in origin tables
- Raw data is extracted into tables with different data types (transaction, block, log…), which will be different for each chain
- For EVM blockchains, logs and traces need to go through a different decoding step for each protocol.
- The extracted and decoded data will be combined with Offchain data to form Transform tables and ready to be used for different purposes.
You can refer to the details of the data flow between Chainslake tables here
Layer design
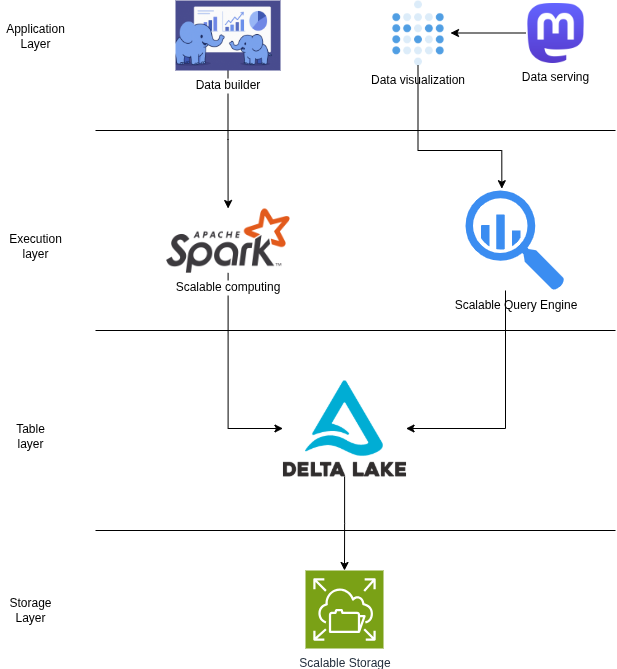
- Storage layer: Where the data is actually physically stored, using Scalable storage to allow for on-demand storage expansion.
- Table layer: Data is organized in the tables (logical) allowing upper-layer applications to work easily instead of working directly with the physical storage layer. The table format used is Delta, column based.
- Execution layer: The execution layer includes Spark jobs that process data (get data from blockchain nodes, extract, decode, transform) and a query engine that queries data from Delta tables. The execution layer is also scalable.
- Application layer: Includes applications that work directly with users:
- Data builder: a programming framework developed by Chainslake, allowing users to program spark jobs, configure, and automate execution. I will share more about this framework in the following articles.
- Data visualization: An application that queries data using SQL and displays the data into analytical charts.
- Data serving: Makes built analytics public to serve other applications.
On-premise Deployment
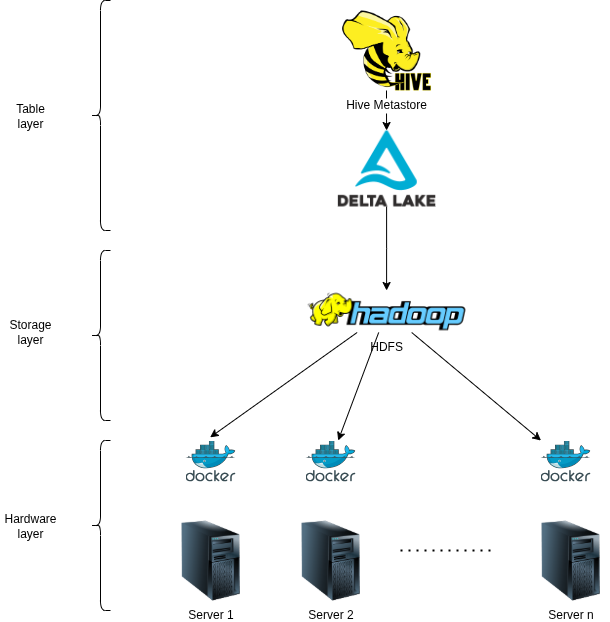
- For storage scalability, Chainslake uses Hadoop HDFS deployed via Docker on each physical Server
- Uses Hive Metastore to store table metadata information allowing upper-layer applications to easily query data from tables.
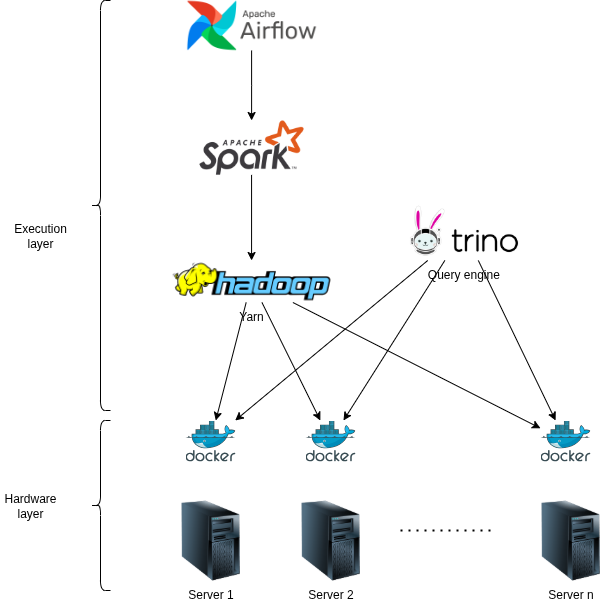
- Spark jobs will be submitted on Hadoop Yarn for computational scalability
- The query engine used is Trino, installed on the cluster via Docker
- Spark jobs are controlled automatically via Airflow.
On-cloud Deployment (AWS)
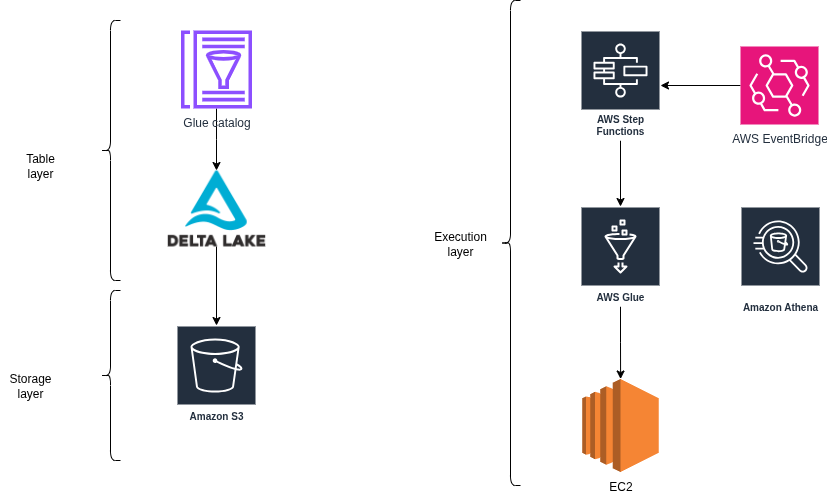
- On-cloud, scalable storage will use AWS S3
- Glue catalog will take on the same task as Hive metastore on On-premise
- Job execution will be done by Glue ETL (similar to Spark)
- AWS Athena will be the query Engine
- Step function and EventBridge will take on the role of automating and scheduling jobs on the system.
Conclusion
In this article, I have introduced an overview of the Chainslake framework, hope you are interested in this product. In the next articles, I will go into more details, see you again!