How to install Hadoop cluster on ubuntu 20.04
- 8 minsApache Hadoop is an open source software project used to build big data processing systems, enabling distributed computing and scaling across clusters of up to thousands of computers with high availability and fault tolerance. Currently, Hadoop has developed into an ecosystem with many different products and services. Previously, I used Ambari HDP to install and manage Hadoop Ecosystem, this tool allows to centralize all configurations of Hadoop services in one place, thereby easily managing and expanding nodes when needed. However, since 2021, HDP has been closed to collect fees, all repositories require a paid account to be able to download and install. Recently, I needed to install a new Hadoop system, so I decided to manually install each component. Although it would be more complicated and time-consuming, I could control it more easily without depending on others. Partly because the new system only had 3 nodes, the workload was not too much. I will record the entire installation process in detail in a series of articles on the topic of bigdata. Everyone, please pay attention and read!
Contents
- Target
- Environment setup
- Download hadoop and configure
- Run on single node
- Add new node to cluster
- Basic user guide
- Conclusion
I am currently consulting, designing and implementing data analysis infrastructure, Data Warehouse, Lakehouse for individuals and organizations in need. You can see and try a system I have built here. Please contact me via email: lakechain.nguyen@gmail.com. Thank you!
Target
In this article, I will install the latest Hadoop version (3.3.4 at the time of writing) on 3 nodes Ubuntu 20.04 and OpenJdk11. For convenience in setup and testing, I will use Docker to simulate these 3 nodes.
Environment setup
First, we create a new bridge network on Docker (If you have not installed Docker, please see the installation instructions here)
$ docker network create hadoop
Next is to create a container on the Ubuntu 20.04 image
$ docker run -it --name node01 -p 9870:9870 -p 8088:8088 -p 19888:19888 --hostname node01 --network hadoop ubuntu:20.04
I’m using MacOS so I need to bind the port from the container to the host machine, you don’t need to do this if you’re using Linux or Windows.
Install the necessary packages
$ apt update
$ apt install -y wget tar ssh default-jdk
Create hadoop users
$ groupadd hadoop
$ useradd -g hadoop -m -s /bin/bash hdfs
$ useradd -g hadoop -m -s /bin/bash yarn
$ useradd -g hadoop -m -s /bin/bash mapred
For security reasons, Hadoop recommends that each service should run on a different user, see details here
Generate ssh-key on each user
$ su <username>
$ ssh-keygen -m PEM -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
Start ssh service
$ service ssh start
Add hostname in file /etc/hosts
172.20.0.2 node01
Note
172.20.0.2is the container ip on my machine, you replace it with your machine ip.
Check if ssh is available
$ ssh <username>@node01
Download hadoop and configure
Go to Hadoop’s download page here to get the link to download the latest version.
$ wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
$ tar -xvzf hadoop-3.3.4.tar.gz
$ mv hadoop-3.3.4 /lib/hadoop
$ mkdir /lib/hadoop/logs
$ chgrp hadoop -R /lib/hadoop
$ chmod g+w -R /lib/hadoop
Next, we need to configure environment variables. Here we will add environment variables to the file /etc/bash.bashrc so that all users on the system can use them.
export JAVA_HOME=/usr/lib/jvm/default-java
export HADOOP_HOME=/lib/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export HDFS_NAMENODE_USER="hdfs"
export HDFS_DATANODE_USER="hdfs"
export HDFS_SECONDARYNAMENODE_USER="hdfs"
export YARN_RESOURCEMANAGER_USER="yarn"
export YARN_NODEMANAGER_USER="yarn"
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
Update environment variables
$ source /etc/bash.bashrc
Also need to update environment variables in the file: $HADOOP_HOME/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/default-java
Hadoop Configuration Settings
-
$HADOOP_HOME/etc/hadoop/core-site.xmlsee full configuration here
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/${user.name}/hadoop</value>
</property>
</configuration>
/home/${user.name}/hadoopis the folder where I save data on HDFS, you can change to another folder if you want.
$HADOOP_HOME/etc/hadoop/hdfs-site.xmlsee full configuration here
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions.superusergroup</name>
<value>hadoop</value>
</property>
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>774</value>
</property>
</configuration>The
dfs.replicationconfiguration sets the actual number of copies stored for a data on HDFS.
-
$HADOOP_HOME/etc/hadoop/yarn-site.xmlsee full configuration here
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>-1</value>
</property>
<property>
<name>yarn.nodemanager.resource.detect-hardware-capabilities</name>
<value>true</value>
</property>
</configuration>Run on 1 node
Format file on Name Node
$ su hdfs
[hdfs]$ $HADOOP_HOME/bin/hdfs namenode -format
$ exit
Run Hadoop services on root account
$ $HADOOP_HOME/sbin/start-all.sh
Result
-
http://localhost:9870/orhttp://172.20.0.2:9870/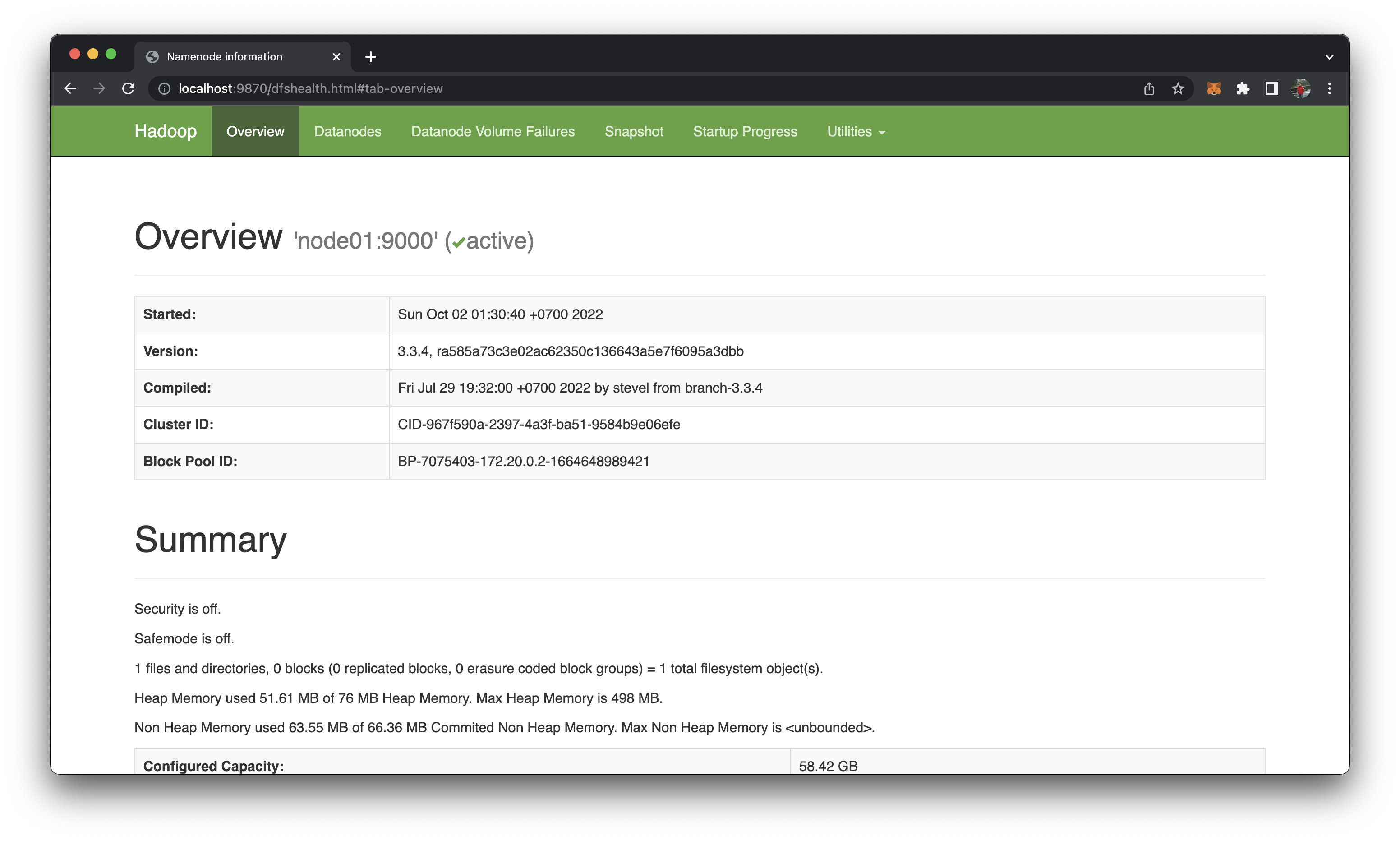
-
http://localhost:8088/orhttp://172.20.0.2:8088/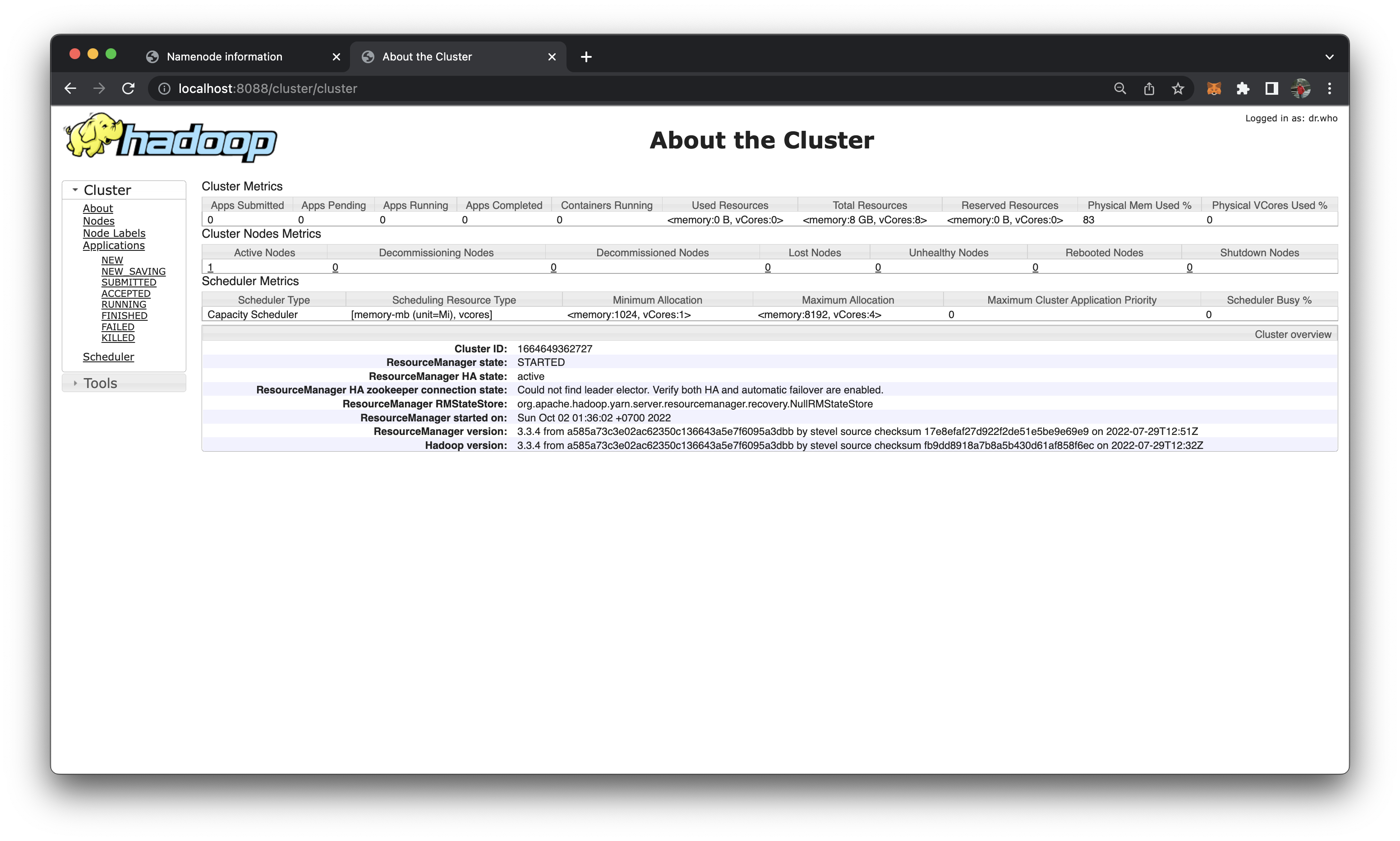
Add new node to cluster
To add a new node to the cluster, perform all the steps above on that node. Because I use Docker, I will create an image from the existing container
$ docker commit node01 hadoop
Run new container from newly created image
$ docker run -it --name node02 --hostname node02 --network hadoop hadoop
On node02 we start ssh service and delete the old data folder
$ service ssh start
$ rm -rf /home/hdfs/hadoop
$ rm -rf /home/yarn/hadoop
Update ip, hostname of Namenode for node02
- File
/etc/hosts
172.20.0.3 node02
172.20.0.2 node01
On node01 we add the ip and hostname of node02
- File
/etc/hosts
172.20.0.2 node01
172.20.0.3 node02
- File
$HADOOP_HOME/etc/hadoop/workers
node01
node02
Then start all hadoop services on node01
$ $HADOOP_HOME/sbin/start-all.sh
Check if node02 has been added
-
http://localhost:9870/dfshealth.html#tab-datanode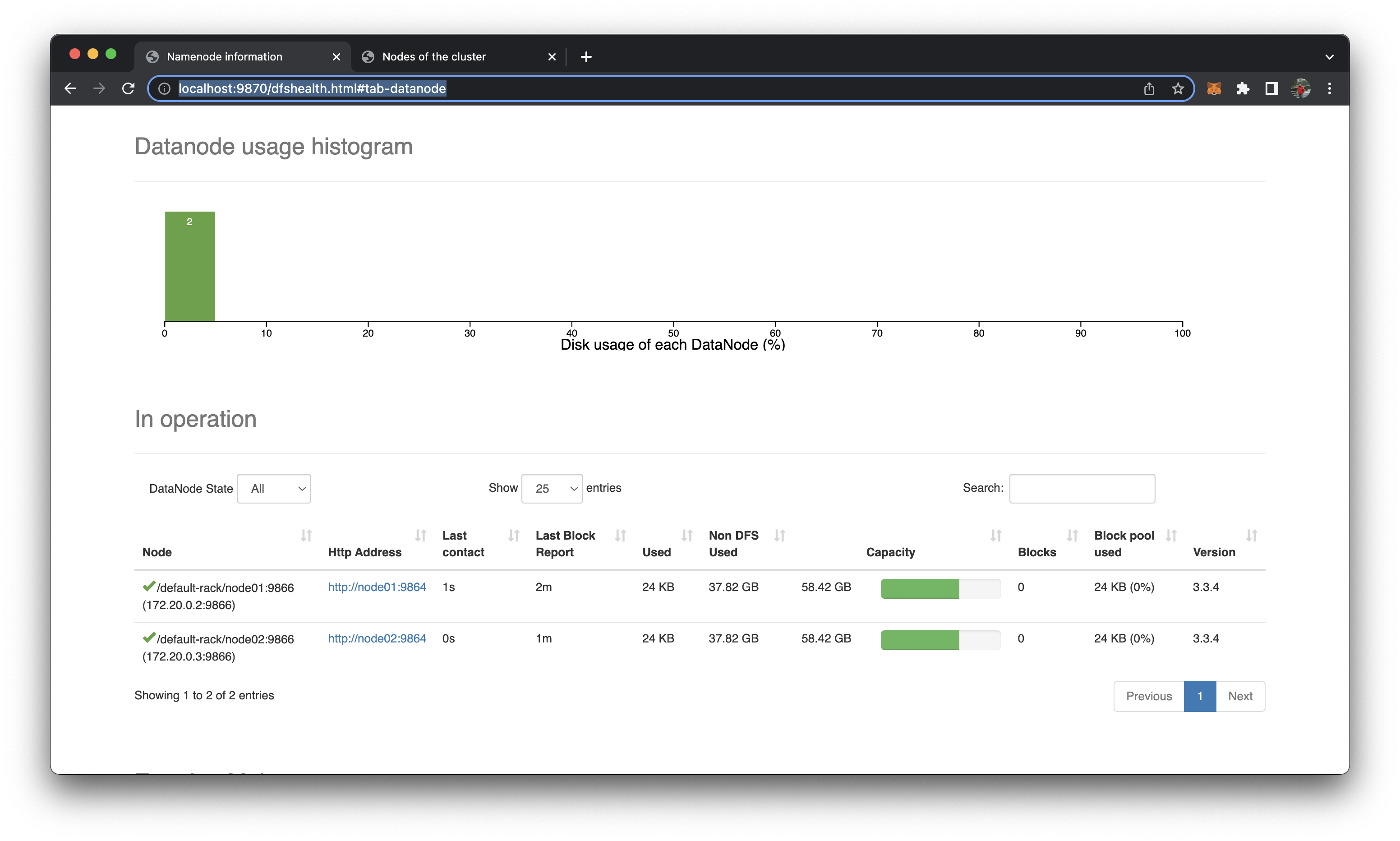
-
http://localhost:8088/cluster/nodes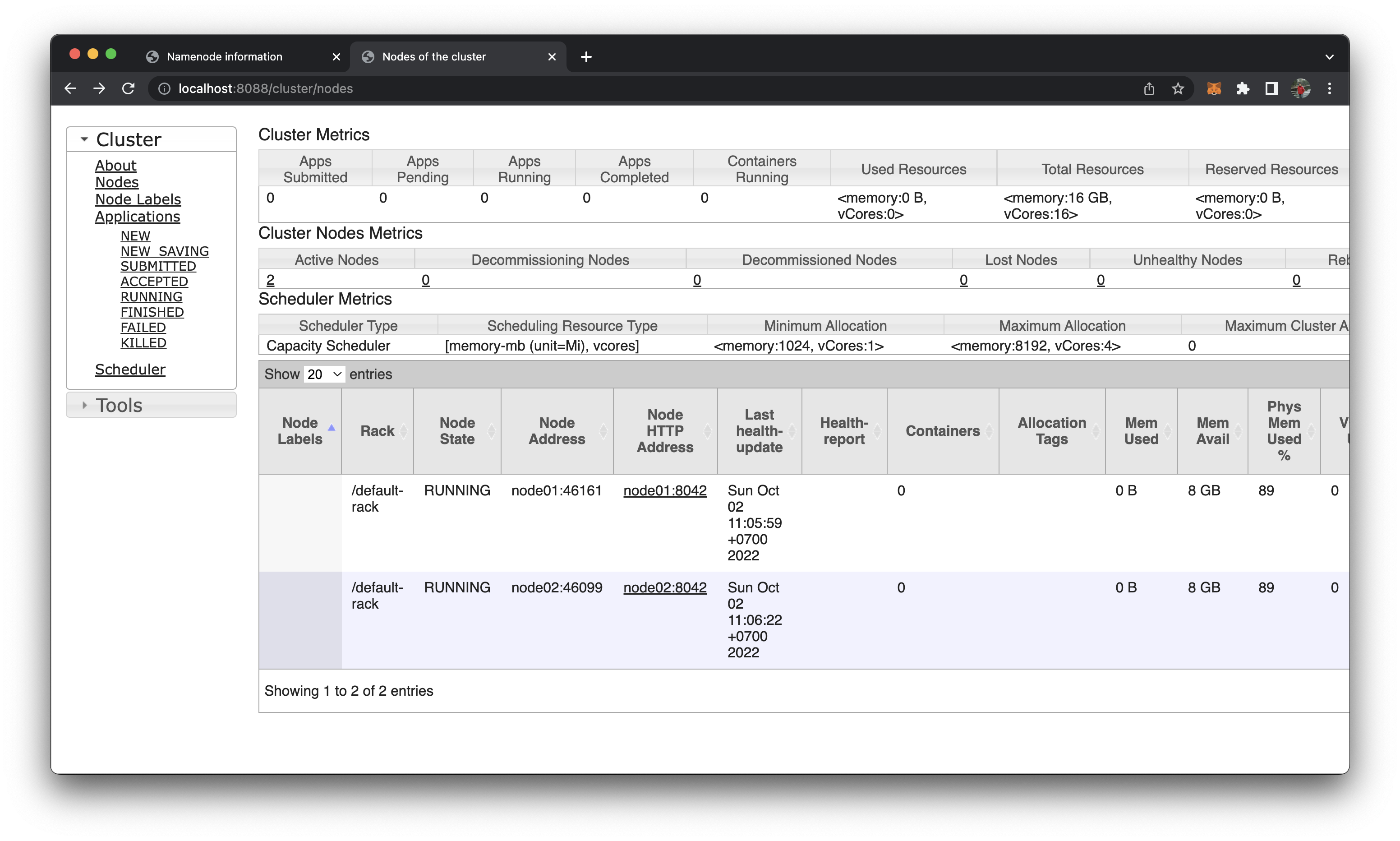
Do the same with node03 and you will get a cluster of 3 nodes
Note that because I cloned node02, node03 from the original node01, there is no need to add the ssh-key of the accounts (because they already use the same ssh-key). If installed on a real system, you need to copy the public key from each account on the namenode and add it to the authorized_keys of the corresponding account on the datanode.
Basic User Guide
To start all services in the Hadoop cluster, we need to go to the master node (in this article, node01) using the root account
$ $HADOOP_HOME/sbin/start-all.sh
The master node needs to have the ip and hostname of all slave nodes in the
/etc/hostsfile and eachhdfs,yarn,mapredaccount of the master node can ssh to the corresponding account on the slave nodes. Each Slave node must be able to connect to the Master node via hostname.
To turn off all services of the Hadoop cluster
$ $HADOOP_HOME/sbin/stop-all.sh
Conclusion
So in this article I have fully introduced my Hadoop installation process, if you have any problems following, please try to solve them yourself :). See you in the next article.

Lake Nguyen
Founder of Chainslake