Giới thiệu Chainslake - Blockchain Lakehouse Framework
- 7 minsChào mọi người, mình là Lake Nguyen, founder của Chainslake - một lakehouse framework dành cho lĩnh vực blockchain và crypto. Chainslake cung cấp giải pháp công nghệ cho khách hàng, giúp họ có thể xây dựng và vận hành blockchain lakehouse phục vụ nhiều mục đích như truy vấn, truy vết giao dịch, theo dõi, cảnh báo, phân tích, dự đoán xu hướng từ dữ liệu hoặc sử dụng dữ liệu để huấn luyện các mô hình AI… Chainslake đang có một trang demo cho khách hàng trải niệm miễn phí tại chainslake.com và một số kênh demo phân tích theo chain, protocol:
- chainslake.com/@bitcoin
- chainslake.com/@ethereum
- chainslake.com/@binance
- chainslake.com/@aave
- chainslake.com/@nftfi
- chainslake.com/@opensea
- chainslake.com/@uniswap
Chainslake đem đến cho khách hàng quyền làm chủ hệ thống và dữ liệu từ đó đảm bảo tính riêng tư và bảo mật cho khách hàng, đồng thời tối ưu được chi phí hạ tầng theo nhu cầu sử dụng. Tuy nhiên điều này cũng đòi hỏi khách hàng cần có những hiểu biết nhất định về thiết kế và cách thức vận hành hệ thống để có thể sử dụng framework hiệu quả. Chính vì vậy, song song với việc phát triển và hoàn thiện framework, mình sẽ viết blog này chia sẻ các kiến thức và kinh nghiệm sử dụng framework, rất mong nhận được sự ủng hộ từ bạn đọc.
Trong bài viết đầu tiên này, mình sẽ giới thiệu tổng quan và thiết kế kiến trúc tổng thể của framework.
Nội dung
Giới thiệu tổng quan
Nếu bạn là một người quan tâm đến lĩnh vực blockchain và crypto, chắc hản là bạn biết dữ liệu trong blockchain (dữ liệu Onchain) được chia sẻ công khai (do tính chất phi tập trung của Blockchain). Điều này cho phép bất kỳ ai cũng có thể tiếp cận và sử dụng dữ liệu Onchain này. Tuy nhiên dữ liệu trong blockchain (thường là dữ liệu giao dịch) được đóng trong các block, sử dụng các cấu trúc dữ liệu đặc biệt để tối ưu cho việc xác thực giao dịch nhưng lại khiến việc truy xuất và phân tích dữ liệu này gặp khó khăn, từ đó đã thúc đẩy sự xuất hiện của các sản phẩm phân tích dữ liệu blockchain.
Về bản chất, tất cả sản phẩm phân tích blockchain đều là sự kết hợp giữa dữ liệu Onchain và tri thức Offchain (bao gồm dữ liệu Offchain, cách thức phối hợp, phân tích, trình bày… hay bất kỳ dữ liệu riêng tư nào khác). Chính phần Offchain mới làm nên sự khác biệt giữa các sản phẩm này. Nếu bạn đang muốn xây dựng một sản phẩm phân tích blockchain của riêng mình hay đơn giản là muốn đảm bảo riêng tư cho phần Offchain của bạn thì bạn có thể cân nhắc sử dụng Chainslake.
Chainslake là công cụ phân tích cho phép bạn xây dựng và vận hành nền tảng dữ liệu một cách riêng tư, nơi mà bạn có thể thoải mái kết hợp dữ liệu Onchain với dữ liệu Offchain của bạn mà không cần lo lắng về các nguy cơ lộ lọt dữ liệu, từ đó có thể phát triển sản phẩm phân tích của riêng bạn.
Đối với một sản phẩm phân tích dữ liệu, đặc biệt là với dữ liệu lớn như Blockchain, vấn đề tối ưu chi phí luôn cần quan tâm đặc biệt, hiểu được điều này Chainslake được thiết kế theo hướng tinh gọn nhưng vẫn dễ mở rộng theo nhu cầu, từ đó giúp tiết kiệm chi phí. Về mặt triển khai, Chainslake có 2 tùy chọn là On-premise trên server vật lý hoặc On-cloud trên AWS.
Kiến trúc thiết kế
Luồng dữ liệu
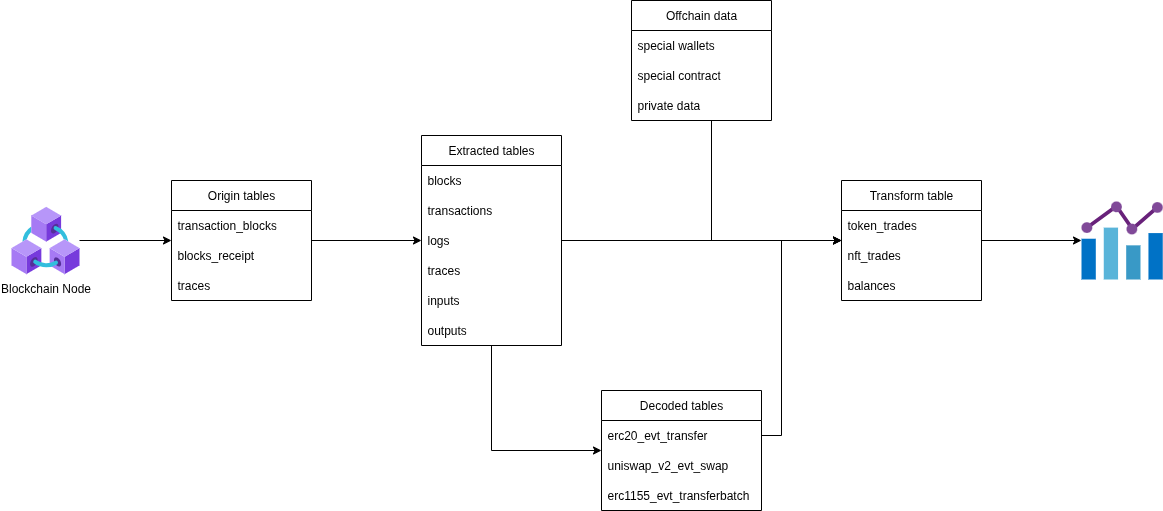
Một cách tổng quan nhất, Luồng dữ liệu của Chainslake được xây dựng như sau:
- Bắt đầu với dữ liệu được lấy từ các Blockchain node (Onchain), dữ liệu thô sau đó được lưu toàn vẹn trong các bảng origin
- Dữ liệu thô được trích xuất thành các bảng với từng loại dữ liệu khác nhau (transaction, block, log…), sẽ khác nhau với từng chain
- Đối với các EVM blockchain dữ liệu logs và traces cần đi qua một bước decode khác nhau với từng protocol.
- Các dữ liệu extract và decoded sẽ được kết hợp cùng dữ liệu Offchain để tạo thành các bảng Transform và sẵn sàng để sử dụng cho các mục đích khác nhau.
Bạn có thể tham khảo chi tiết về luồng dữ liệu giữa các bảng của Chainslake tại đây
Thiết kế phân tầng
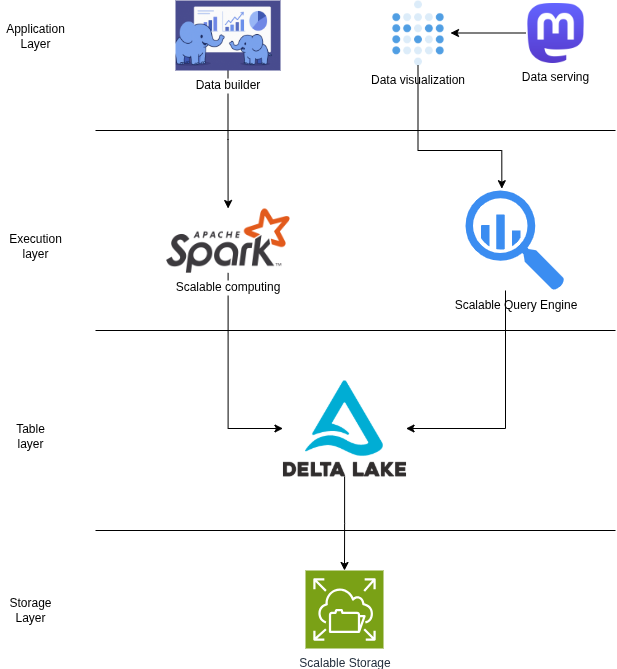
- Storage layer: Nơi dữ liệu thực sự được lưu trữ vật lý, sử dụng Scalable storage cho phép khả năng mở rộng lưu trữ theo nhu cầu.
- Table layer: Dữ liệu được tổ chức dưới dạng bảng (logic) cho phép các ứng dụng tầng trên có thể làm việc dễ dàng thay vì làm việc trực tiếp với tầng lưu trữ vật lý. Format bảng sử dụng là Delta, column based.
- Execution layer: Tầng thực thi bao gồm các Spark job xử lý dữ liệu (lấy dữ liệu từ blockchain node, extract, decode, transform) và query engine truy vấn dữ liệu từ các bảng Delta. Tầng thực thi cũng có khả năng mở rộng theo nhu cầu (Scalable).
- Application layer: Gồm các ứng dụng làm việc trực tiếp với người dùng:
- Data builder: một framework lập trình được phát triển bởi Chainslake, cho phép người dùng lập trình các spark job, cấu hình, tự động hóa thực thi. Mình sẽ nói kỹ hơn về framework này trong các bài viết sau.
- Data visualization: Một ứng dụng truy vấn dữ liệu bằng SQL và trình diễn dữ liệu thành các biểu đồ phân tích.
- Data serving: Đưa các phân tích đã xây dựng public ra ngoài để phục vụ các ứng dụng khác.
Triển khai On-premise
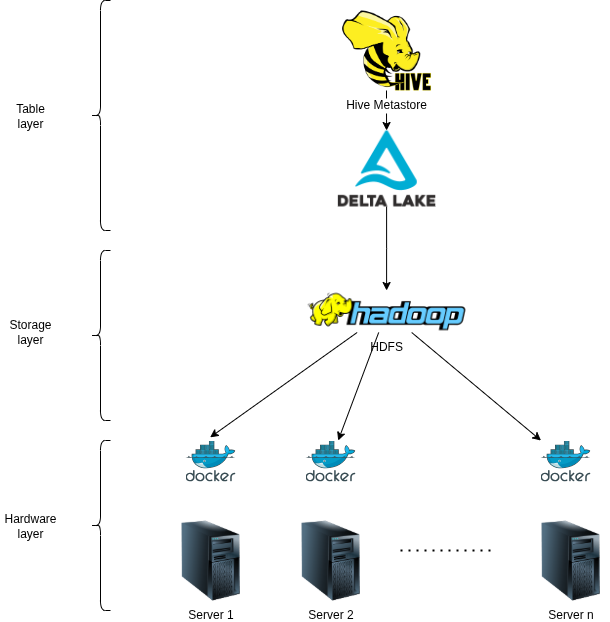
- Để có khả năng mở rộng về mặt lưu trữ, Chainslake sử dụng Hadoop HDFS triển khai qua Docker trên mỗi Server vật lý
- Sử dụng Hive Metastore để lưu trữ các thông tin metadata của bảng cho phép các ứng dụng tầng trên dễ dàng truy vấn dữ liệu từ các bảng.
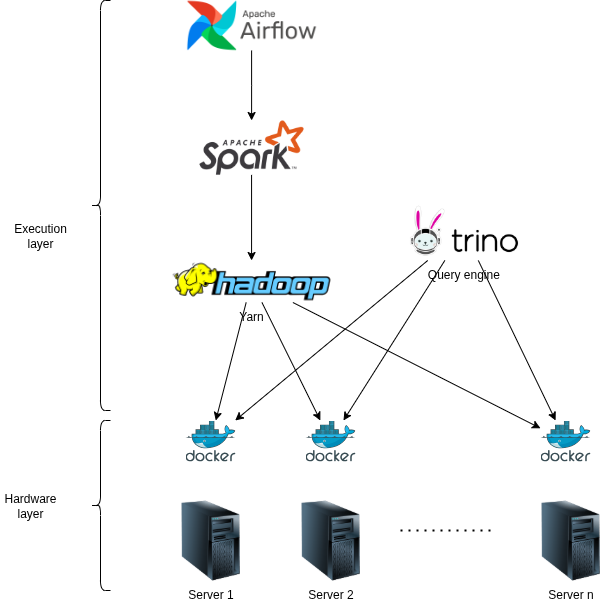
- Các Spark job sẽ được submit trên Hadoop Yarn để có khả năng mở rộng về mặt tính toán
- Query engine sử dụng là Trino, được cái đặt trên cụm thông qua Docker
- Các Spark job được điều khiển tự động qua thông qua Airflow.
Triển khai On-cloud (AWS)
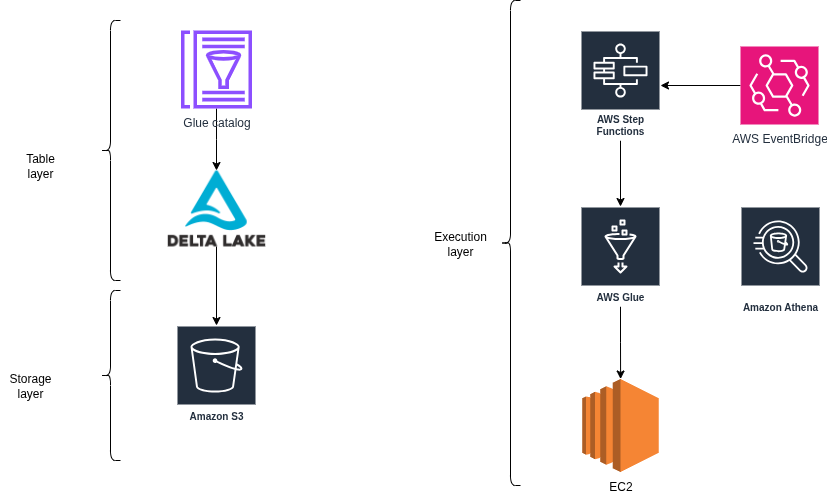
- Trên On-cloud, scalable storage sẽ sử dụng AWS S3
- Glue catalog sẽ đảm nhận nhiệm vụ giống Hive metastore trên On-premise
- Việc thực thi các job sẽ do Glue ETL (tương tự như Spark)
- AWS Athena sẽ làm query Engine
- Step function và EventBridge sẽ đảm nhận vai trò tự động hóa và lập lịch cho các job trên hệ thống.
Kết luận
Trong bài viết này mình đã giới thiệu một cách tổng quan về Chainslake framework, hi vọng các bạn cảm thấy hứng thú với sản phẩm này. Trong các bài viết tới mình sẽ đi vào chi tiết nhiều hơn, hẹn gặp lại!