Config Hadoop enable hight availability
- 7 minsThrough the tests in the article introducing HDFS (you can review here), we have seen that the system can still operate normally, data is not affected even when some Datanodes have errors. However, this system has not yet achieved high availability because there is still a weakness at the Namenode, when the Namenode has an error, the entire HDFS cluster will not be able to operate. In this article, I will guide you on how to configure a Hadoop cluster with multiple Namenodes to achieve High Availability.
Contents
I am currently consulting, designing and implementing data analysis infrastructure, Data Warehouse, Lakehouse for individuals and organizations in need. You can see and try a system I have built here. Please contact me via email: lakechain.nguyen@gmail.com. Thank you!
Overview
First of all, I will briefly review the role of Namenode in the HDFS system. It is the management node, where Metadata information such as file names, directory trees, access rights, and block locations in the Datanode are stored. Thanks to Namenode, reading and writing data on HDFS becomes as simple as on a normal file system. Namenode is like a map in the HDFS system. Any data reading and writing operations on HDFS must go through Namenode, which makes it a weak point in the entire system.
To solve this problem, the HDFS system needs more Namenodes, but this does not mean that all Namenodes can work together. In a multi-application, multi-threaded, and distributed environment, having many Namenodes working together will certainly lead to conflicts if there is no consensus mechanism. In fact, the HDFS architecture with HA only allows 1 Namenode to be active at a time, it will receive requests to read and write data and update Metadata. Other Namenodes are in standby mode, they will continuously synchronize data from the Active Namenode to ensure that their Metadata data is always updated with the latest from the Active NameNode.
When the Active Namenode fails, another Standby Namenode will be activated to become the new Active Namenode. The selection of the Standby Namenode uses the Leader Election algorithm, the following is the architecture of the HDFS system with High Availability.
System architecture
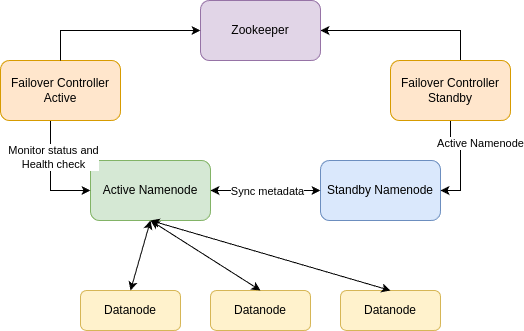
- Active Namenode: The Namenode is currently active, acting as the main Namenode to manage and store Metadata information for the HDFS system.
- Standby Namenode: The Namenodes are in standby mode, they will synchronize Metadata data from the Active Namenode
- Failover Controller: The Namenode Manager is run on each node with a Namenode, with the task of monitoring the operating status of the Active Namenode and activating the Standby Namenode when necessary.
- Zookeeper Service: Select which Standby Namenode will be activated, I will present more about Zookeeper in the following articles.
Install and configure
I will enable HA for the existing Hadoop cluster (you can review the installation instructions here). The current Hadoop cluster already has a Namenode on node01, I will configure it to have another Namnode on node02.
First we will install Zookeeper, you can find the latest version of Zookeeper here
$ wget https://dlcdn.apache.org/zookeeper/zookeeper-3.9.1/apache-zookeeper-3.9.1-bin.tar.gz
$ tar -xzvf apache-zookeeper-3.9.1-bin.tar.gz
$ mv apache-zookeeper-3.9.1-bin /lib/zookeeper
$ chgrp hadoop -R /lib/zookeeper
$ chmod g+w -R /lib/zookeeper
Note: For simplicity, I will install Zookeeper on 1 node (node01), in reality to ensure HA we should install Zookeeper on 3 nodes
Create user Zookeeper
$ useradd -g hadoop -m -s /bin/bash zookeeper
Configure Zookeeper in file /lib/zookeeper/conf/zoo.cfg:
tickTime=2000
initLimit=5
syncLimit=2
dataDir=/home/zookeeper/data
clientPort=2181
Run Zookeeper service:
[zookeeper]$ /lib/zookeeper/bin/zkServer.sh start
Next, I will configure node02 to become a Namenode. Note that the configuration must be done on all nodes of the Hadoop cluster. Before starting, I will shutdown the Hadoop cluster:
On node01
$ $HADOOP_HOME/sbin/stop-all.sh
Add configuration to file $HADOOP_HOME/etc/hadoop/hdfs-site.xml
<configuration>
...
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node01:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node02:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node01:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node02:9870</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>file:///home/hdfs/ha-name-dir-shared</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node01:2181</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence(hdfs:22)</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hdfs/.ssh/id_rsa</value>
</property>
</configuration>
Edit configuration in file $HADOOP_HOME/etc/hadoop/core-site.xml
<configuration>
...
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
</configuration>
Create a share folder in the home directory of the hdfs user:
[hdfs]$ mkdir ~/ha-name-dir-shared
Note: Private key of hdfs user must be generated using RSA algorithm, you can do it with the following command:
[hdfs]$ ssh-keygen -m PEM -P '' -f ~/.ssh/id_rsa
After configuring all nodes, next I will synchronize name data (Metadata) from node01 to node02
Enable Namenode on node01
hdfs@node01:~$ $HADOOP_HOME/bin/hdfs --daemon start namenode
Initialize name data for node02
hdfs@node02:~$ hdfs namenode -bootstrapStandby
Go back to node1 to initialize data in Zookeeper, then shut down Namenode on node01
hdfs@node01:~$ hdfs zkfc -formatZK
hdfs@node01:~$ $HADOOP_HOME/bin/hdfs --daemon stop namenode
Now the installation and configuration is done, let’s test it out.
Test
Restart all Hadodop services
hdfs@node01:~$ $HADOOP_HOME/sbin/start-all.sh
Check on the Namenode interface of node01 and node02:
-
http://node01:9870/dfshealth.html#tab-overview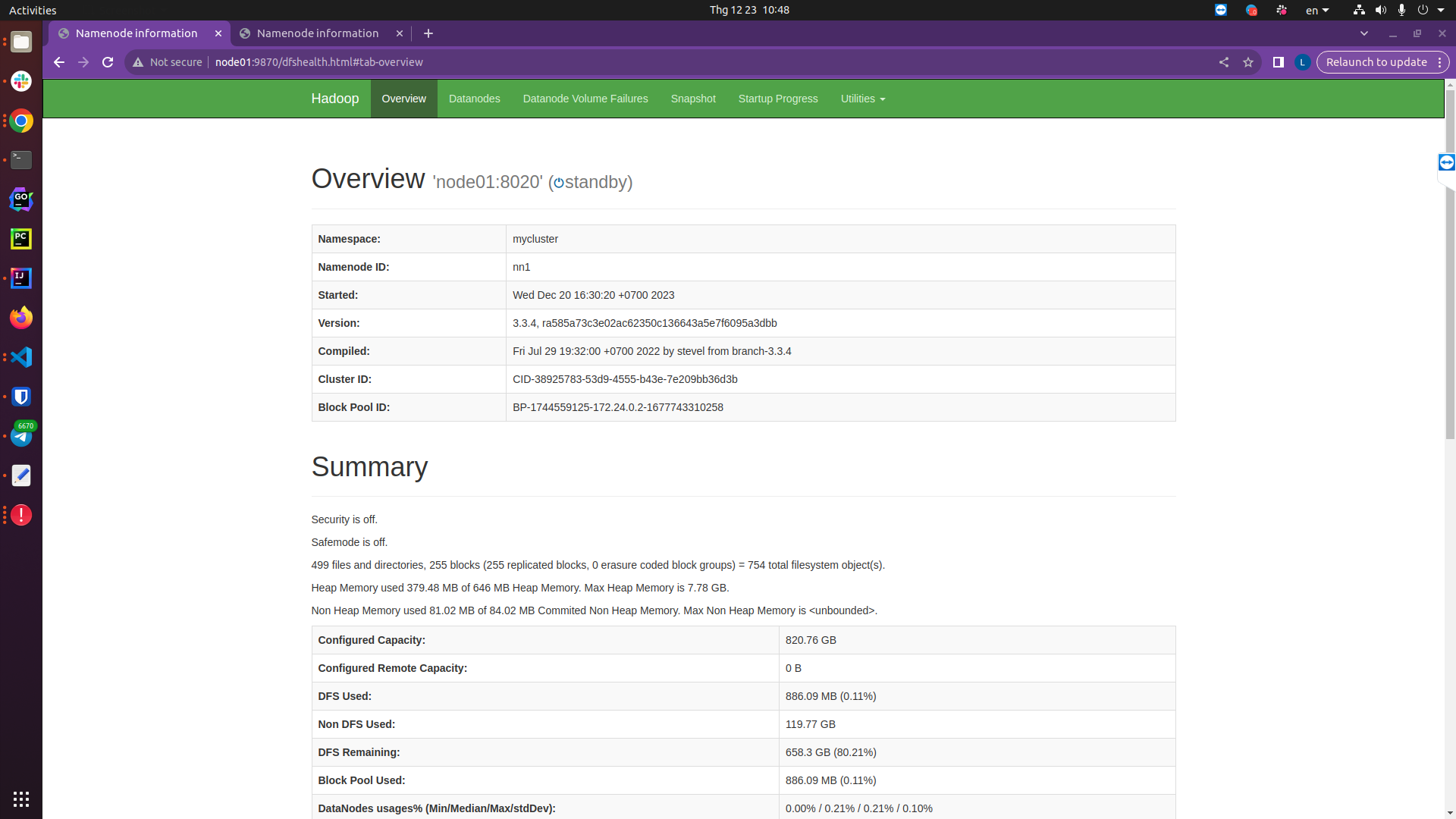
-
http://node02:9870/dfshealth.html#tab-overview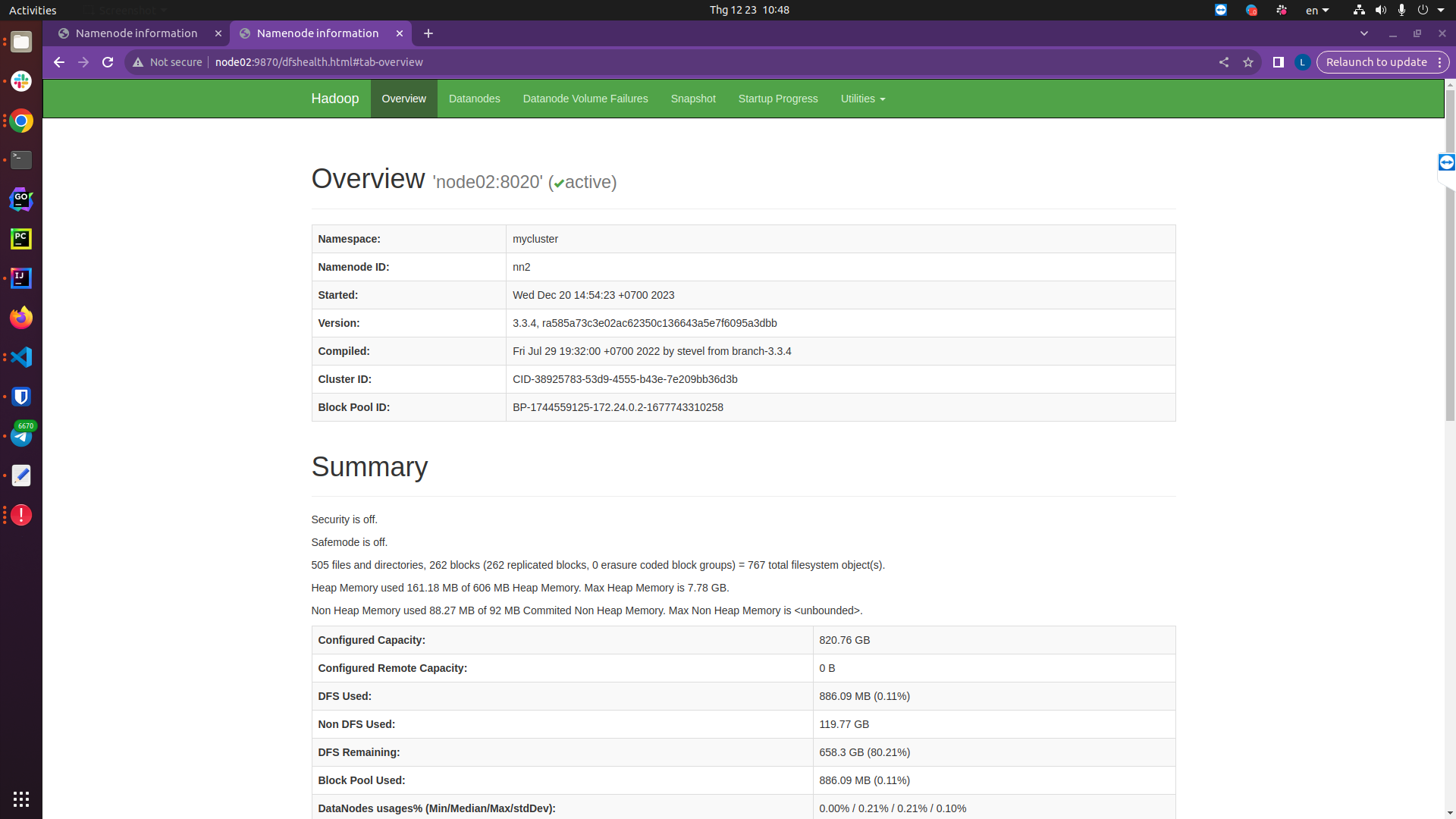
You can see that Namenode 02 is active, while Namenode 01 is standby, now I will turn off namenode 02 to see what happens
On node02:
hdfs@node02:~$ $HADOOP_HOME/bin/hdfs --daemon stop namenode
Now namenode01 is activated to change the state to active:
-
http://node01:9870/dfshealth.html#tab-overview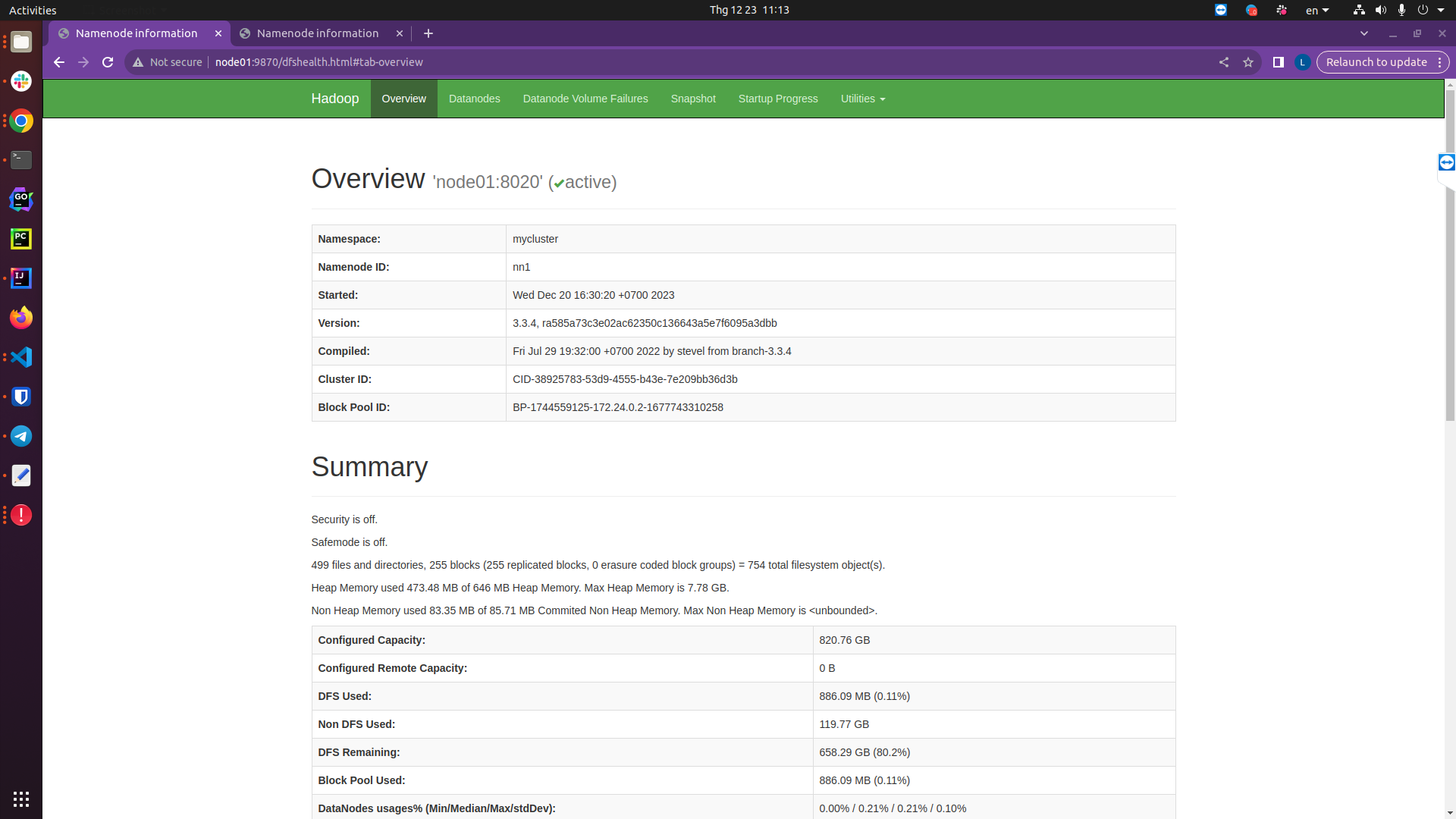
To check and change the status of namenodes manually we can use the hadmin utility:
hdfs@node01:~$ hdfs haadmin [-ns <nameserviceId>]
[-transitionToActive <serviceId>]
[-transitionToStandby <serviceId>]
[-failover [--forcefence] [--forceactive] <serviceId> <serviceId>]
[-getServiceState <serviceId>]
[-getAllServiceState]
[-checkHealth <serviceId>]
[-help <command>]
Note: When enabling HA on HDFS, we will need to reconfigure applications that use HDFS:
Reconfigure the $SPARK_HOME/conf/hive-site.xml and $HIVE_HOME/conf/hive-site.xml files:
<configuration>
...
<property>
<name>hive.metastore.warehouse.dir</name>
<value>hdfs://mycluster/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
...
</configuration>
Change the location of schema and tables in the datawarehouse
root@node01:~$ hive --service metatool -updateLocation hdfs://mycluster hdfs://node1:9000
Configure hive catalog in Trino $TRINO_HOME/etc/catalog/hive.properties:
hive.config.resources=/lib/hadoop/etc/hadoop/core-site.xml,/lib/hadoop/etc/hadoop/hdfs-site.xml
Conclusion
In this article, I have shown you how to Enable HA on the HDFS system, this will help the HDFS system operate with high availability, thereby improving the stability of the entire system. See you again in the next articles.

Lake Nguyen
Founder of Chainslake