Building blockchain Data Warehouse (part 2)
- 12 minsIn the previous article, I introduced to you a design and installation of a Data Warehouse based on the Hadoop platform and some Opensource technologies, you can review here. In this article, I will use this DWH to apply to a specific problem of analyzing Blockchain data, you can try it in hear. Because the content of the article will focus on the data analysis system, I will not go too deep into Blockchain technology but will only present issues related to EVM Blockchain data to explain the design of the system.
Contents
- EVM Blockchain Overview
- Design Architecture
- Scanner
- Decoder
- Spellbook
- Visualization
- Automation
- Conclusion
I am currently consulting, designing and implementing data analysis infrastructure, Data Warehouse, Lakehouse for individuals and organizations in need. You can see and try a system I have built here. Please contact me via email: lakechain.nguyen@gmail.com. Thank you!
EVM Blockchain Overview
Bitcoin shows us that the first version of Blockchain is a decentralized ledger (you can review the article here), where all money transfer transactions are recorded. EVM Blockchain is the next generation of Blockchain, it includes a layer of chains that were born later since Ethereum was introduced, including many popular chains such as: Ethereum, Binance Smart Chain, Polygon… (you can see more in this list this). Ethereum has helped Blockchain become more flexible and versatile instead of just being able to perform money transfer transactions, I will summarize some new points of EVM Blockchain as follows:
Smart Contract: is a program that is located on the EVM Blockchain, similar to software located on a computer. Smart Contract will be activated when the user calls a function of it, at this time Smart Contract will execute that function exactly as it is programmed. Smart Contract is usually written in the language Sodility, below is a simple example:
// SPDX-License-Identifier: GPL-3.0
pragma solidity >=0.4.16 <0.9.0;
contract SimpleStorage {
uint storedData;
function set(uint x) public {
storedData = x;
}
function get() public view returns (uint) {
return storedData;
}
}Ethereum Virtual Machine (EVM): Is a virtual machine running on the nodes of the EVM Blockchain used to execute the functions of Smart Contracts.
Native cryptocurrency: Is the main currency on each chain, for example on Ethereum it is Ether (ETH), Binance Smart Chain is Binance (BNB). Native cryptocurrency is created according to the mechanism of each different chain, and is used to pay transaction fees on that chain.
Transaction: When a user transfers money, deploys a contract (puts a new contract on the blockchain) or performs a function of a Smart Contract, a transaction will be created.
Gas: Is a unit to measure the computational volume of the EVM when performing a transaction. To perform a transaction, the user must pay a gas fee to the network.
Token Standards: These are standards for Smart Contracts for Tokens, which include the functions that a Smart Contract must have to meet the standards. Below are 3 popular Token Standards on EVM Blockchain:
-
ERC20: This is a token standard that is very similar to Native Cryptocurrency, meaning you can store it in a wallet, transfer tokens, the difference is that ERC20 is created from Contracts, so it is much more flexible and versatile than Native Cryptocurrency. Stable Coins (Tokens with a price pegged to a fiat currency: eg USDT, BUSD…), Wrap Tokens (Tokens that replace Native Cryptocurrency, eg WBNB, WBTC…) are all part of ERC20.
-
ERC721: Is the token standard of NFT (Non-fungible Token), each token of a contract is different and cannot be replaced with each other, used to identify digital assets.
-
ERC1155: Is also the token standard of NFT, but each token of a contract can be divided into smaller ones.
Blockchain Explorer To understand what has happened and is happening on EVM Blockchain, we need to use Blockchain Explorer, a website that allows users to look up information and view data on the blockchain in a more user-friendly way. For example: etherescan.io, bscscan.com, polygonscan.com…
Design Architecture
To design this system, I referred to the descriptions of Dune Analyst, a startup providing Blockchain data analysis infrastructure, valued at 1 billion dollars in February 2022.
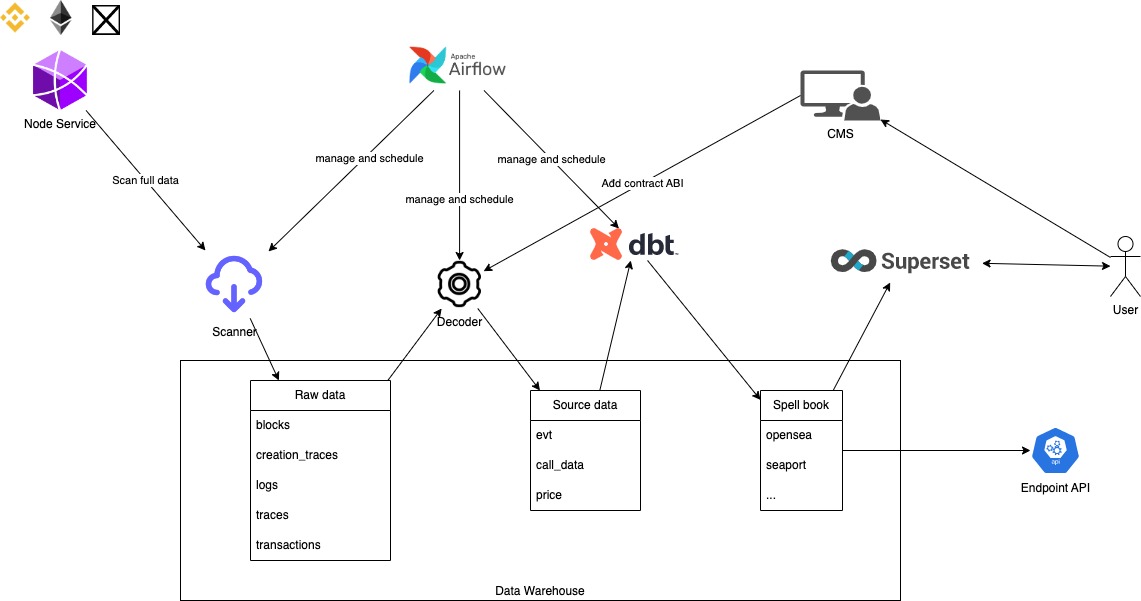
- Scanner: Has the function of scanning data from EVM blockchain through Node service and storing raw data into DWH.
- Decoder: Raw data on EVM blockchain is encrypted data, so Decoder plays the role of decoding raw data into structured Source data for easy use.
- Spellbook: Is a collection of data tables made public by Dune for the purpose of data analysis on EVM blockchain, you can refer to the source code of Spellbook here
- Other components such as: DBT, Airflow, Superset I introduced in the previous article, you can review here.
Scanner
Before talking about Scanner, I will briefly describe the data on EVM Blockchain. I will take an example of a Transfer transaction of USDT, an ERC20 stable coin on the Ethereum network. In the overiew tab, you can see the following information (click on more details to see all the information):
- Transaction Hash: is the unique identifier of this transaction, you can use TxHash to find the exact transaction.
- Status: The status of the transaction is usually Success or Pending
- Block: Blocknumber of the transaction, indicating which block this transaction is closed in.
- From: The wallet address of the transaction
- To: The address to receive the request, here is the contract address of the USDT token.
- Value: The amount of ETH (Native cryptocurrency) sent to the contract.
- Transaction fee: Transaction fee in ETH
- Gas Price: Gas price at the time of the transaction in ETH
- Gas Limit & Usage: The maximum amount of gas and the amount of gas used for the transaction
- Burnt & Txn Savings Fees: The amount of ETH burned and the amount of eth returned to the validator when performing the transaction. You can learn more about the mint burn mechanism of ethereum here.
- Input Data: The data sent when performing the transaction, in this transaction is the call to perform the transfer function of the contract. You can click on View input as Original to view the raw data or Decode input data to view the data after decoding.
Switch to the logs tab and you will see a list of logs generated when performing this transaction, each event log includes the following information:
- Address: the contract address that generates this event log, here is the contract of the USDT token
- Name: The name of the event log
- Topics: contains information indexed in the event log, in which topic[0] is the signature (unique identifier) of this event log, used to distinguish this event from other events.
- Data: Data in the event log.
Scanner will perform the task of getting raw transaction and event log data from the Node Service and saving it to DWH, I use the Web3j library to get data from the Node Service. Below is a sample code in Scala for your reference:
import org.web3j.protocol.Web3j
import com.google.gson.Gson
val rpcUrl = <URL_YOUR_RPC_SERVICE>
val web3 = Web3j.build(new HttpService(rpcUrl))
val gson = new Gson()
val blockNumber = new DefaultBlockParameterNumber(1234)
val query = new EthFilter(blockNumber, blockNumber, java.util.Collections.emptyList[String]())
val eventlogs = gson.toJson(web3.ethGetLogs(query).sendAsync().get().getLogs)
println(eventlogs)
val blockData = web3.ethGetBlockByNumber(blockNumber, true).sendAsync().get().getBlock
val transactions = gson.toJson(blockData)
println(transactions)
With a huge number of blocks to retrieve data: 16.6 million blocks on Ethereum and 25.6 million blocks on BSC, in order to maximize the number of requests to Node Service, I use Spark to scan multiple blocks in parallel.
Decoder
The data after being retrieved is encoded raw data, to decode it we need the ABI (Application Binary Interface) of the contract. ABI is like a technical guide that allows us to decode raw data into structured data with clear meaning suitable for analysis. Details about ABI you can see here. To get the ABI of the contract we can use Blockchain Explorer, for example with the USDT token contract you can go here, on this page you can see both the source code and ABI of the contract. The decoder is designed to include a CMS that allows users to upload the contract’s ABI file (because not all contracts have full ABI on Explorer), the decoder will decode the raw data and push it into the decoded table, you can see the description of the decoded table here. Below is a sample code to decode event log data and function call data for your reference:
import com.esaulpaugh.headlong.abi.{Event, Function}
import com.esaulpaugh.headlong.util.Strings
import org.web3j.abi.EventEncoder
import java.util
val eventABIJson = <String abi json of one event>
val e = Event.fromJson(eventABIJson)
val eventSignature = EventEncoder.buildEventSignature(e.getCanonicalSignature)
println(eventSignature)
val topic1, topic2, topic3, topic4: String // Topics of one Event
val data: String // Data of one Event
val topics = new util.ArrayList[Array[Byte]]
topics.add(Strings.decode(topic1.replace("0x", "")))
if (topic2 != null && topic2 != "") {
topics.add(Strings.decode(topic2.replace("0x", "")))
}
if (topic3 != null && topic3 != "") {
topics.add(Strings.decode(topic3.replace("0x", "")))
}
if (topic4 != null && topic4 != "") {
topics.add(Strings.decode(topic4.replace("0x", "")))
}
val extractedData = e.decodeArgs(topics.toArray(new Array[Array[Byte]](topics.size())), Strings.decode(data.replace("0x", "")))
println(extractedData)
val functionABIJson = <String abi json of one Function>
val f = Function.fromJson(functionABIJson)
val methodId = Strings.encode(f.selector())
println(methodId)
val data: String // Input of one Transaction
val extractedData = f.decodeCall(Strings.decode(data.replace("0x", "")))
println(extractedData)
Spellbook
After getting the source code of Spellbook, you proceed to install it according to the instructions here, check the doc of Spellbook on the interface:
To run each table separately on Spellbook, use the following command:
$ dbt run --select +<model_name>
Before running a model, you need to check whether the data tables it depends on are complete or not by checking the DAG Graph of that model. For example, I want to run the model: tofu_bnb_trades with the following DAG Graph:
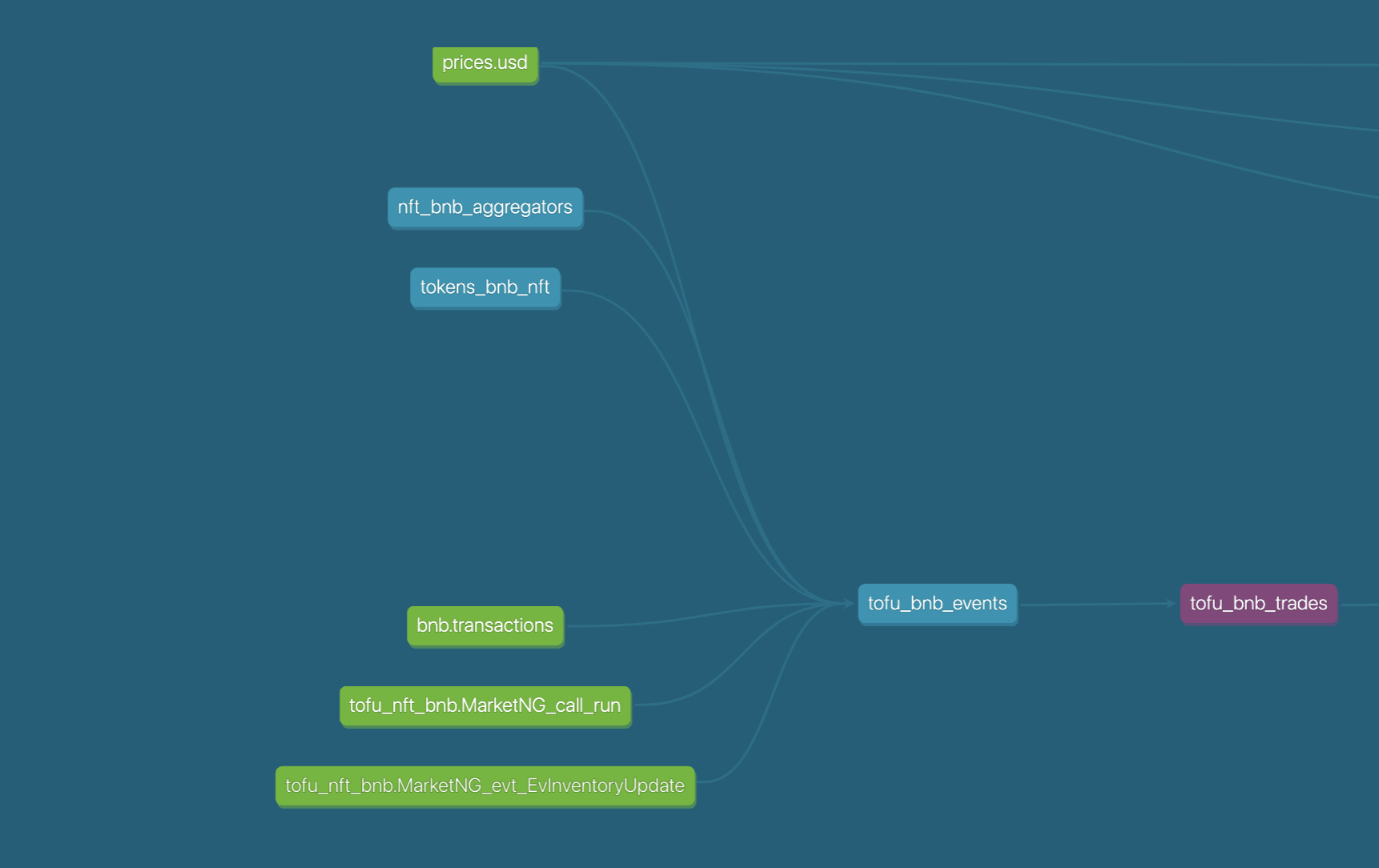
We see that this model is dependent on datasources (green), so we need to prepare datasource tables (by using Decoder or getting more data from other sources) before we can run this model.
Conclusion
That’s all for today’s article, I will continue to write more content for this article in the next updates. See you again

Lake Nguyen
Founder of Chainslake